🦍 Gorilla: Large Language Model Connected with Massive APIs
Gorilla OpenFunctions
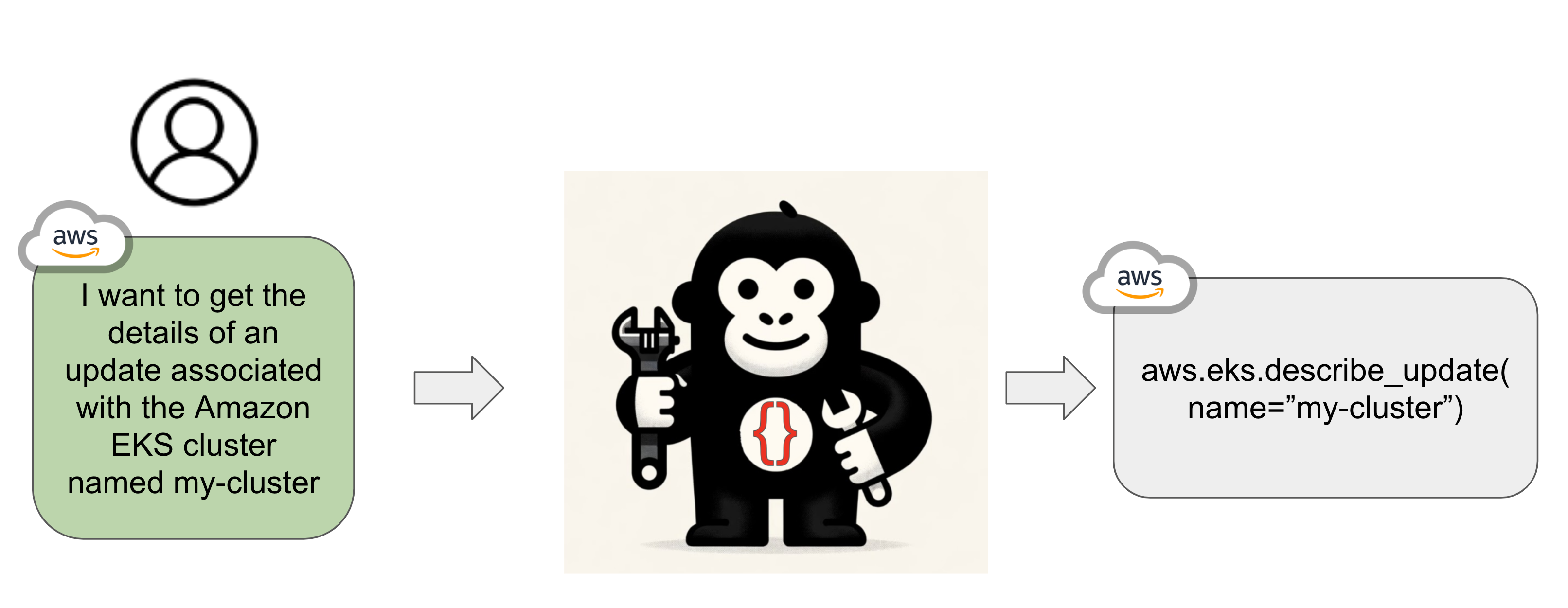
Gorilla OpenFunctions is a drop-in open-source alternative. Given a prompt and API, Gorilla returns the correctly formatted function call. With Apache 2.0 licensed models, you can integrate OpenFunctions into your applications directly!
OpenFunctions is designed to extend Large Language Model (LLM) Chat Completion feature to formulate executable APIs call given natural language instructions and API context. Imagine if the LLM could fill in parameters for a variety of services, ranging from Instagram and DoorDash to tools like Google Calendar and Stripe. Even users who are less familiar with API calling procedures and programming can use the model to generate API calls to the desired function. Gorilla OpenFunctions is an LLM that we train using a curated set of API documentation, and Question-Answer pairs generated from the API documentations. We have continued to expand on the Gorilla Paradigm and sought to improve the quality and accuracy of valid function calling generation. This blog is about developing an open-source alternative for function calling similar to features seen in proprietary models, in particular, function calling in OpenAI's GPT-4. Our solution is based on the Gorilla recipe, and with a model with just 7B parameters, its accuracy is, surprisingly, comparable to GPT-4.
Quick Links:
- Colab Notebook: OpenFunctions
- Dataset: GitHub
- Models on HuggingFace: gorilla-llm/gorilla-openfunctions-v0
How to use OpenFunctions
 OpenFunctions can write accurate API calls. Beyond popular python packages and hyperscaler CLIs, it extends to any callable function with API documentation!
OpenFunctions can write accurate API calls. Beyond popular python packages and hyperscaler CLIs, it extends to any callable function with API documentation!
Using Gorilla OpenFunctions is straightforward:
- Define Your Functions: Provide a JSON file containing descriptions of your custom functions. Each function should contain fields:
name(the name of the API),api_call(how to invoke this API),description(which describes the functionality of the API), and lastly,parameters(a list of parameters pertaining to the API call). Below is an example of API documentation that can feed into OpenFunctions. - Install the openai client with
pip install openai==0.28 - Ask Your Question: Describe what you want as if talking to another person.
- Get Your Function Call: The model will return a Python function call based on your request. This opens up possibilities for developers and non-developers alike, allowing them to leverage complex functionalities without writing extensive code.
function_documentation = {
"name" : "Order Food on Uber",
"api_call": "uber.eat.order",
"description": "Order food on uber eat given a list of items and the quantity of items respectively",
"parameters":
[
{
"name": "restaurants",
"description": "The restaurants user wants to order from"
},
{
"name": "items",
"description": "A list of order user wants to order from restaurants"
},
{
"name": "quantities",
"description": "A list of quantities corresponding to the items ordered"
}
]
}
I want to order five burgers and six chicken wings from McDonald.
Input:
get_gorilla_response(prompt="I want to order five burgers and six chicken wings from McDonald.",
functions=[function_documentation])Output:
uber.eat.order(restaurants="McDonald",item=["chicken wings", "burgers"], quantity=[6,5])OpenFunctions Performance Benchmarking
We are benchmarking our model against current state-of-the-art model, GPT-4-0613, as well as GPT-4's and GPT-3.5-turbo's function calling features. Our test dataset consists of 116 distinct query and API documentation pairs, crafted by feeding few-shot examples into GPT-3.5-turbo and asking the model to generate APIs from different domains, including travel, finance, scheduling meetings.
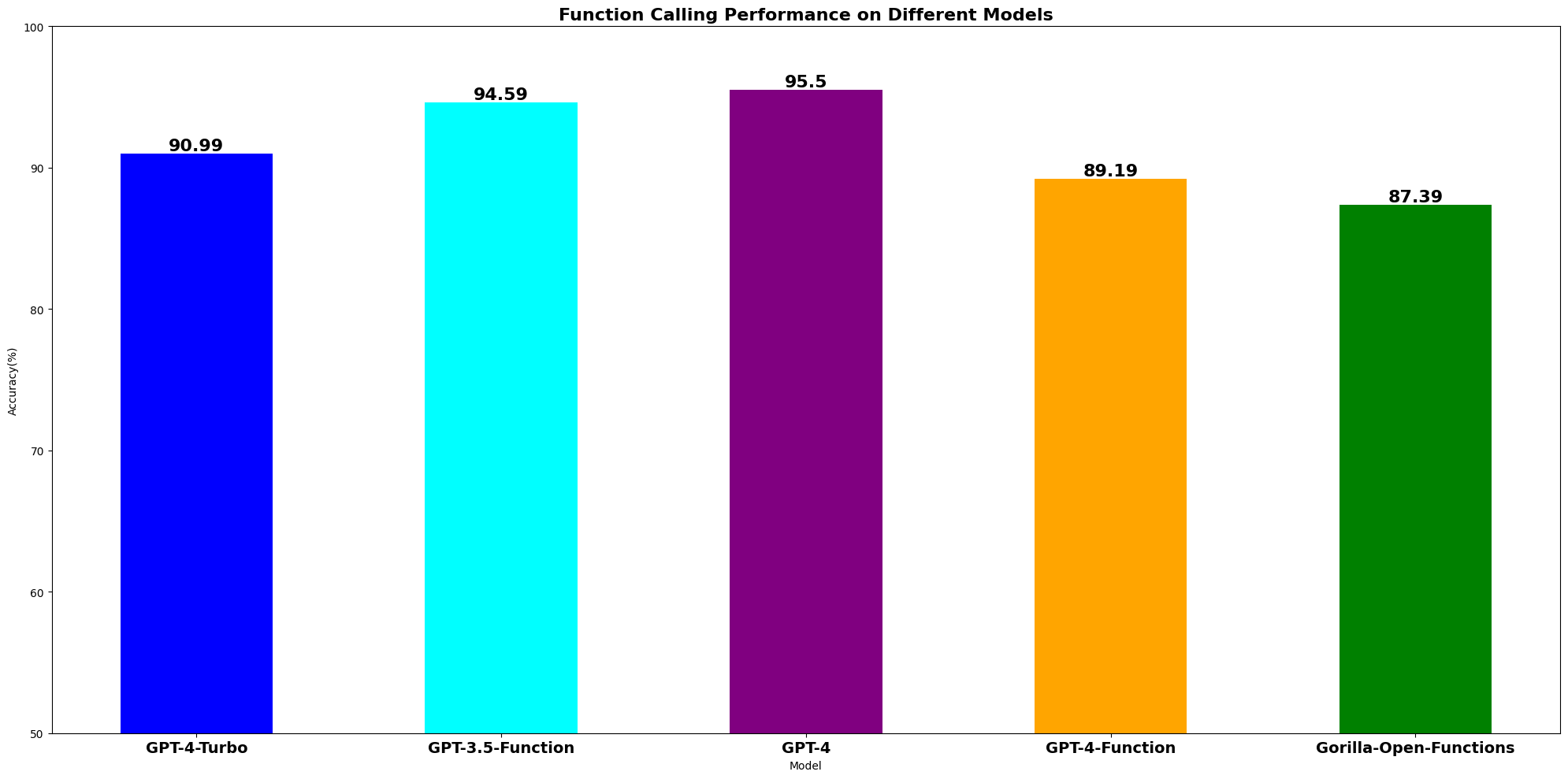 Surprisingly, we observe that GPT-4 and GPT-3.5 function calling perform better than the state-of-the-art GPT-4-Turbo and GPT-4 model tailored for function calling. Our OpenFunctions model is closely behind with tiny margin.
Surprisingly, we observe that GPT-4 and GPT-3.5 function calling perform better than the state-of-the-art GPT-4-Turbo and GPT-4 model tailored for function calling. Our OpenFunctions model is closely behind with tiny margin.
To evaluate the quality of the output, we perform a side-by-side examination between a model's output and the 'gold' answer. From the graph above, we can see that GPT-4 and GPT-3.5-Turbo return function calls with a higher success rate, around 95%, compared to GPT-4 function calls. Our 7B parameter llama-v2-based OpenFunctions model follows GPT-4 function calling with a 87.39% success rate.
Below are two examples of GPT-4 generating unsatisfactory results:
"Query": "Determine the monthly mortgage payment for a loan
amount of $200,000, an interest rate of 4%, and a
loan term of 30 years.",
"GPT-4 output":
"{"name": "finance.calculate_mortgage_payment",
"arguments": "{"loan_amount": 200000,
"interest_rate": 4,
"loan_term": 30}"
}",
"Gold answer": "finance.calculate_mortgage_payment(
loan_amount=200000,
interest_rate=0.04,
loan_term=30)"
"Query": "Order me six pack of potato chips and eight
pack of chocolate from target near Berkeley.",
"GPT-4 output":
"{ "name": "target.get",
"arguments": "{
"loc": "Berkeley",
"item": ["six pack of potato chips",
"eight pack of chocolate"],
"quantity": [1, 1]}
}",
"Gold answer": "target.order(
loc=Berkeley,
item=["potato chips", "chocolate"],
quantity=[6,8])"
As we can see from the above examples, even GPT-4's function calling isn't able to guarantee satisfactory results in the analysis of function parameters. Here, we have a detailed breakdown of the percentage of success and failure in our test data:
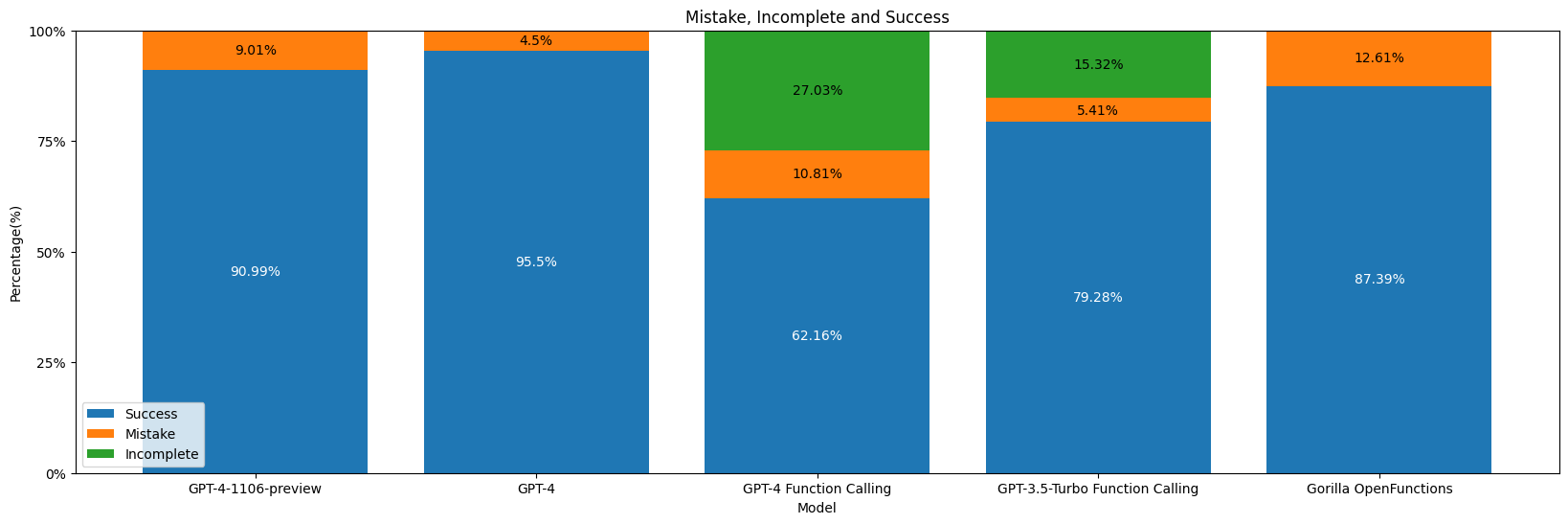 While the standard GPT-4 is able to produce definitive results, OpenAI's function calling model will often ask follow up question if the required parameters are not supplied, which results in a state of no result.
While the standard GPT-4 is able to produce definitive results, OpenAI's function calling model will often ask follow up question if the required parameters are not supplied, which results in a state of no result.
When calling to OpenAI's function calling models, if the required parameters are not supplied within the instruction, this leads the function calling models to output "follow-up" questions requesting the required parameters. This results in "incomplete" status as displayed in above graph. We treat "incomplete" execution as "success" during our accuracy calculation because the model recognized the missing parameters successfully. Note that this is consistent across all evaluations. Our OpenFunctions model, as well as regular GPT-4, due to its chat completion nature, will fill up the required parameters with placeholders or default values, allowing undisturbed generation.
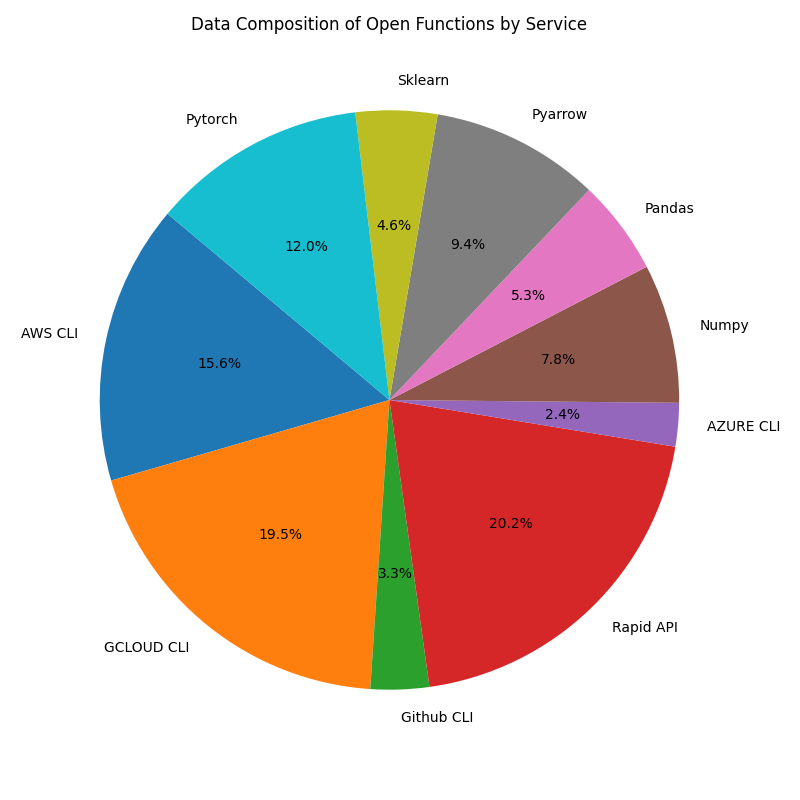
OpenFunctions Data Composition
The dataset we trained our model on consists of 14,189 instruction-API pairs. We curated the API documentations from 3 sources:
- Python packages: We curated the python APIs from the official documentation of the packages. We intentionally chose packages that are clean and well-documented. We found that those packages typically belonged to scientific computing, and machine learning domains.
- RapidAPI: We curated RapidAPI documents from the API marketplace. Since RapidAPI typically makes requests to an API endpoint, we format the API documentation to have function
requests.getwith properties:url,headers,params. Completing this function will enable the user to callrequests.getsuccessfully to the API endpoint. - Command line tools from cloud providers: Lastly we relied on CLI documentation from AWS, Azure, and other hyperscalers. We use these documents to construct python-like function calling.
For each API documentation, we generate three distinct instruction-API pairs as our training data. This instruction and "model" answer pairs are self-generated using few-shot examples of correctly utilizing the API documentations to make accurate function calls. We explicitly prompt the model to take advantage of features like complex value-type, and more parameters if the specific API has the feature.
Code Function Calling APIs vs. REST APIs
When curating the dataset, we observed that API calling can be roughly divided into 2 categories:
- Code Function Calling APIs
- REST APIs
First, the Code Function Calling APIs are typically seen in external python packages like Numpy, Sklearn, etc. These APIs are well-defined, and can be easily formatted. Therefore, by just knowing the 'api_name' e.g. numpy.sum(), and the 'arguments' specification, we can formulate an executable function API. Due to its stable format, and fixed locality, it takes relatively fewer datapoints to bake in the behavior for these APIs during training. This is reflected in how we chose the data-mixture for training.
The RESTful APIs account for a significant portion of the APIs on the internet, powering most services.
These APIs are typically hosted by third parties and offer a variety of functionalities ranging from
financial services to weather forecasting. Oftentimes, RESTful APIs contain three parameters in their metadata:
url, header, and params.
The url contains the API endpoints, header usually contains authentication information, and params contain
the 'information' queried to the API endpoint.
Using requests.get, we can properly query the endpoint.
However, the parameters of REST APIs can exist in different locations.
For example, parameters can be embedded within the URL, e.g.,
gorilla.berkeley.edu/{param1}/{param2}. Another way to represent parameters
embedding can be gorilla.berkeley.edu/?query=param1.
The different methods of calling a REST API can make it challenging for our model to handle complex REST API calls.
To account for this, we relied upon different sources of REST APIs, such as RapidAPI, Postman API, etc to diversify our API database and generate more accurate REST APIs.
Models and Capabilities!
We are happy to release two models: gorilla-openfunctions-v0 and gorilla-openfunctions-v1.
The gorilla-openfunctions-v0 LLM is a 7B parameter model trained on top of the 7B LLaMA-v2-chat instruction-tuned model.
It takes-in the users prompt along with a SINGLE API call and returns the function with the right arguments.
gorilla-openfunctions-v1 is a 7B parameter model trained on top of the 7B LLaMA-v2 pre-trained model. gorilla-openfunctions-v1
is our advanced model that takes-in the users prompt along with MULTIPLE API calls and returns the function with the right arguments.
It also supports parallel functions! gorilla-openfunctions-v1 is in early pre-view, and you can expect it to get much better over the next few days!
All of the results in this blog are generated using gorilla-openfunctions-v0.
We hope you enjoyed this blog post. We would love to hear from you on Discord, Twitter (#GorillaLLM), and GitHub.
If you would like to cite Gorilla:
@inproceedings{patil2024gorilla,
title={Gorilla: Large Language Model Connected with Massive APIs},
author={Patil, Shishir G. and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E.},
year={2024},
journal={Advances in Neural Information Processing Systems}
}