🦍 Gorilla: Large Language Model Connected with Massive APIs
Blog 1: Gorilla LLM
Introduction to Gorilla LLM

Gorilla LLM can write accurate API calls, including Kubernetes, GCP, AWS, Azure, OpenAPI, and more. (Salesforce, servicenow, and datadog coming soon!) Gorilla outperforms GPT-4, Chat-GPT and Claude, significantly reducing hallucination errors.
Gorilla is designed to connect large language models (LLMs) with a wide range of tools, services, and applications exposed through APIs. Imagine if ChatGPT could interact with thousands of services ranging from Instagram and Doordash to tools like Google Calendar and Stripe to help you accomplish tasks. You could ask to book a meeting for your collaborators, order their favorite foods, and pay for it. This may be how we interact with computers and even the web in the future. Gorilla is an LLM that we train using a concept we call - retriever-aware training, that can pick the right API to perform a task, that a user can specify in natural language. We also introduce an Abstract Syntax Tree (AST) based sub-tree algorithm, which for the first time can measure hallucination of LLMs!
The use of API's and Large Language Models(LLMs) has changed what it means to program. Previously, building complex models required extensive time and specialized skills. Now with tools like the HuggingFace API, an engineer can set up a deep learning pipeline with a few lines of code. Instead of searching through StackOverflow and sifting through documentation, developers can ask models like GPT for solutions and receive immediate, actionable code with docstrings. Yet, employing off-the-shelf LLMs to generate precise API calls is impractical as there are millions of available API's which are frequently updated. Gorilla connects LLM's with API's, a system which takes in an instruction like "build me a classifier for medical images" and outputs the corresponding imports and API calls, along with a step-by-step explanation of the process. Gorilla uses self-instruct fine-tuning and retrieval to enable LLMs to accurately select from a large, overlapping, and changing set tools expressed using their APIs and API documentation. With the development of API generation methods comes a question of how to evaluate, as many APIs will have overlapping functionality with nuanced limitations and constraints. Thus, we construct APIBench, a large corpus of APIs including Kubernetes, AWS, GCP, Azure, GitHub, Conda, Curl, Sed, Huggingface, Tensorflow, Torch Hub, and develop a novel evaluation framework which uses sub-tree matching to check functional correctness and measures hallucination.
Using APIBench, we trained Gorilla, an Apache 2.0 licensed, 7B LLM model with document retrieval and show that it significantly outperforms both open-source and closed-source models like Claude and GPT-4 in terms of API functionality accuracy as well as a reduction in API argument hallucination errors.
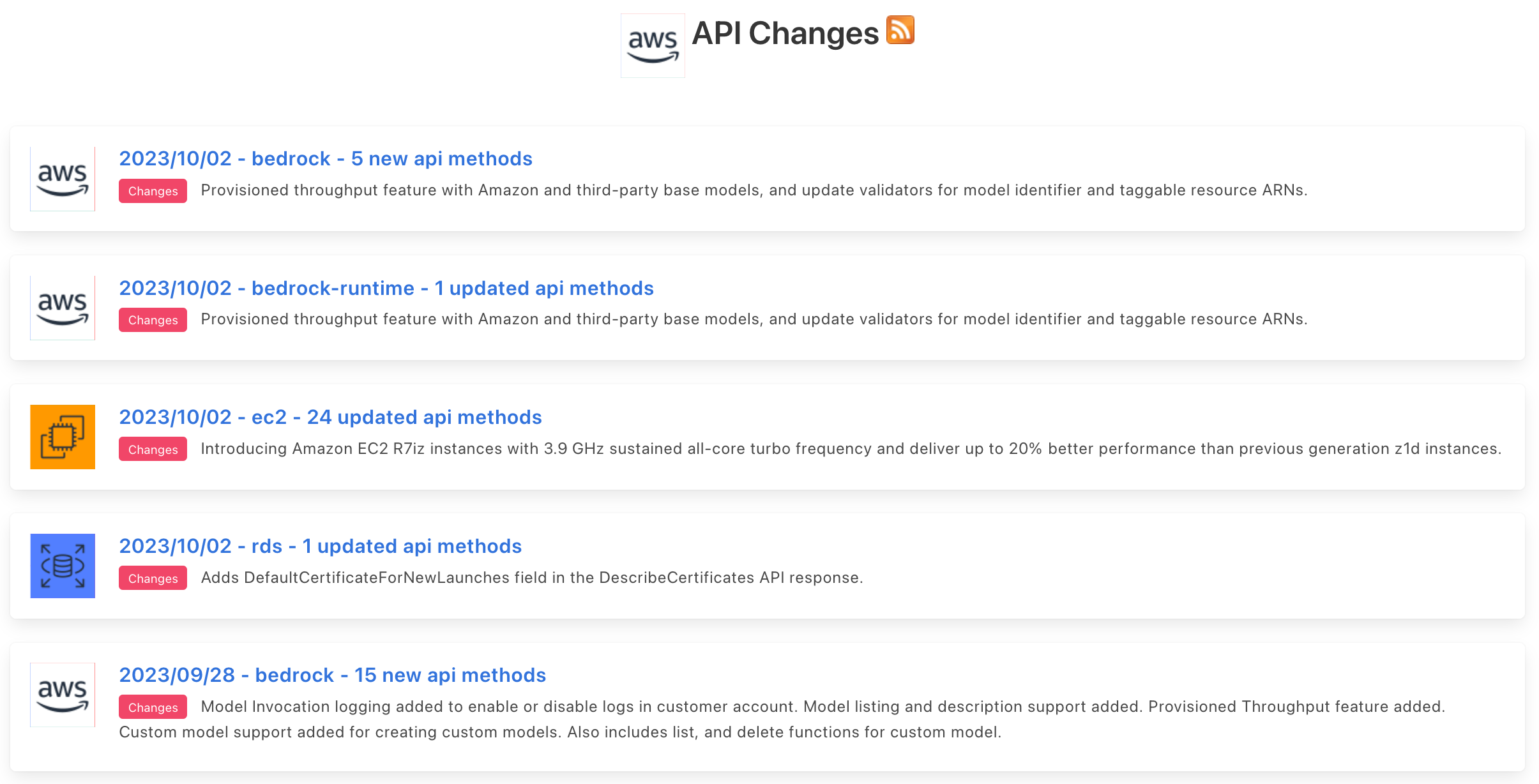
APIs evolve frequently! For example, there were 31 API modifications for AWS APIs just yesterday.
Keeping up with frequently evolving data
APIs are known to evolve frequently - more frequently than it is possible to re-train LLMs. So, how can LLMs keep up with this, and not serve the user out-lawed APIs? To handle this, Gorilla, can be used for inference in two modes: zero-shot and with retrieval. In zero-shot, during inference, user provides the prompt in natural language. This can be for a simple task (e.g, "I would like to identify the objects in an image"), or you can specify a vague goal, (e.g, "I am going to the zoo, and would like to track animals"). This prompt (with NO further prompt tuning) is fed to the Gorilla LLM model which then returns the API call that will help in accomplishing the task and/or goal. In retrieval mode, the retriever first retrieves the most up-to-date API documentation stored in APIZoo, an API Database for LLMs. Before being sent to Gorilla, the API documentation is concatenated to the user prompt along with the message "Use this API documentation for reference:" The output of Gorilla is an API to be invoked. The retriever aware inference mode, enables Gorilla to be robust to frequent changes in APIs! We have open-sourced our APIZoo, and in our continued commitment to the open-source community, today we've released an additional ~20k meticulously documented APIs including KubeCtl, GCP, Azure, AWS, GitHub, etc. We will continue to add more APIs to APIZoo, and welcome contributions from the community!
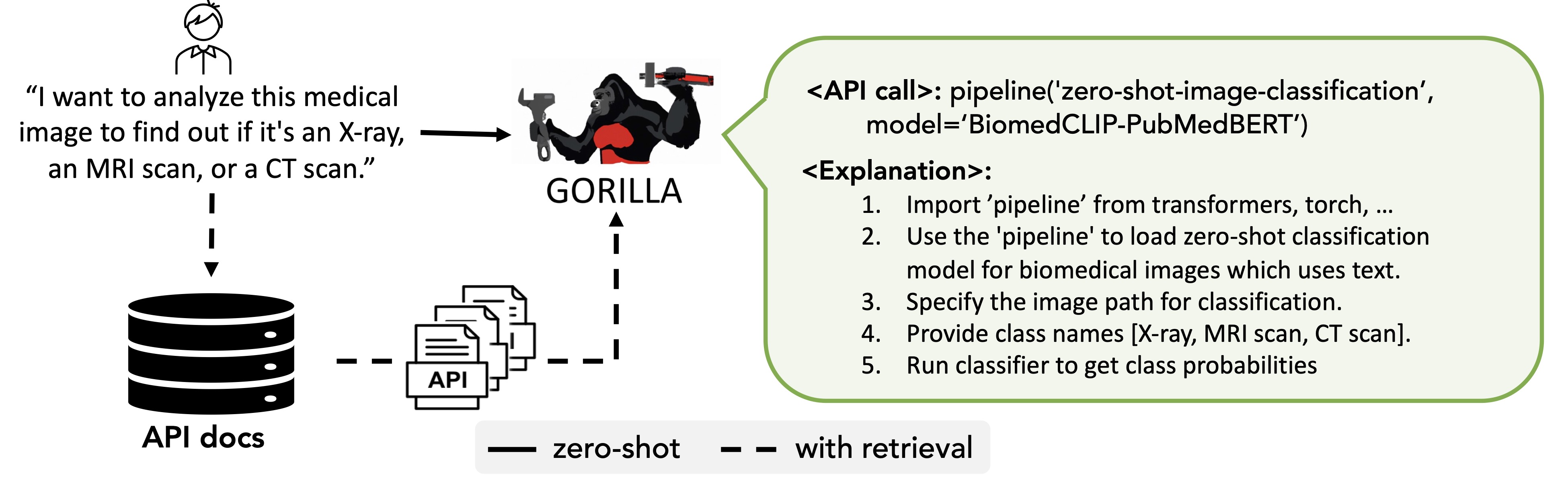
Gorilla, can be used for inference in two modes: zero-shot and with retrieval. In zero-shot, the prompt is directly fed to the Gorilla LLM model. In retrieval mode, the retriever first retrieves the most up-to-date API documentation stored in APIZoo.
Love at First Query: The Untold Bond of LLMs and Retrievers
If you are deploying LLMs in production today, you might be augmenting your model with retrievers such as in Retriever Augmented Generation (RAG) paradigms. Given, most LLMs today are used with retrievers, shouldn't the training recipe for the LLM consider this!! In Gorilla, we consider retrievers to be first class citizens, and train our models to be retriever aware. If you are thinking about integrating LLMs with llamaindex, vector databases such as Weviate, etc check out our blog post on Retrieval Aware Training (RAT) where we teach LLMs to "work-together" with retrievers!

Examples of API calls. In this example, for the given prompt GPT-4 presents a model that doesn't exist, and Claude picks an incorrect library. In contrast, our Gorilla model can identify the task correctly and suggest a fully-qualified API call.
Reality Bytes: When LLMs See Things That Aren't There
Hallucination is the center of discussions for all things LLMs. In the context of API generation, hallucination can be defined as the model generating API calls that do not exist. An LLM generation can be in-accurate or it could be hallucinated. One does not mean the other. For example, if the user asks for a classifier for medical images, if the model generates a Stripe API call for a image classifier - it is hallucination, since it doesn't exist! On the other hand, if the model recommends to use the Stripe API for checking your balance, it is an incorrect usage of the API, but at least not made up (noh-hallucinated). In our blog on hallucination measurement we describe Gorilla's innovative approach of using Abstract Syntax Trees (ASTs) to measure hallucination of the generated API calls. Though not generalizable to all tasks, to the best of our knowledge, Gorilla is the first to measure and quantify hallucination for LLM generations!
How to use Gorilla?
Gorilla is a open-source artifact from UC Berkeley! You can try Gorilla in a few different ways. The easiest is through our Colab notebook. Our hosted Gorilla model can be a drop in replacement for your OpenAI Chatcompletion API calls. Here is a Colab notebook notebook, demonstrating how you could use Gorilla along with Langchain agents. For those of you who are interested in playing around with our models, or would like to host it yourself, the Gorilla models are open-sourced and available on HuggingFace. You can also try Gorilla in your CLI - the most popular way to use Gorilla! Just pip install gorilla-cli to talk to your command line in plane english and have Gorilla come up with the right CLI command for you!
We hope you enjoyed this blog post. We would love to hear from you on Discord, Twitter (#GorillaLLM), and GitHub.
This post was authored by Lisa Dunlap, who is a PhD student at UC Berkeley advised by Joey Gonzalez in Sky Computing Lab and Trevor Darrell in BAIR. Lisa's research focuses on evaluating, advising, and monitoring vision models from a data-centric angle, and is currently working on making vision models more robust with language, training on low-quality datasets, and discovering concepts in large scale datasets.
If you would like to cite Gorilla:
@inproceedings{patil2024gorilla,
title={Gorilla: Large Language Model Connected with Massive APIs},
author={Patil, Shishir G. and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E.},
year={2024},
journal={Advances in Neural Information Processing Systems}
}