🦍 Gorilla: Large Language Model Connected with Massive APIs
Blog 2: Hallucination
Reality Bytes: How to Measure Hallucinations in LLMs

Gorilla LLM can write accurate API calls, including Kubernetes, GCP, AWS, Azure, OpenAPI, and more. (Salesforce, servicenow, and datadog coming soon!) Gorilla outperforms GPT-4, Chat-GPT and Claude, significantly reducing hallucination errors.
Imagine you ask your grandmother for her famous strawberry rhubarb pie recipe. She misspeaks occasionally and tells you to “break the strawberry” when she likely meant to say “cut the strawberries”. Unlike casual stories about her college days, you need accurate information in order to actually bake the pie this weekend, so you recognize that she misspoke and ask her to clarify. Language models have the similar tendency to “misspeak” or hallucinate, which leads to challenges in API usage since concrete actions must be taken. In Gorilla, imagine we ask the LLM “generate an API call for a vision model to identify ripe strawberries”. One of the following may happen
- We get lucky! The API call picks the state-of-the-art classifier: CLIP. `torch.hub.load('pytorch/vision:v0.10.0', 'CLIP')
- We called a valid API but the wrong one :(The LLM is inaccurate. By this, we mean it did not accurately understand the user's specification. For example, the model might be a text-embedding model: `torch.hub.load('pytorch/vision:v0.10.0', 'RoBERTa')
- Wishful thinking! The LLM hallucinates a nonexistent model: BerryPicker. `torch.hub.load('pytorch/vision:v0.10.0', 'BerryPicker')
ASTs allow us to define equivalence preserving rewrites such as populating default arguments (⇒). This is helpful in checking differently expressed programs or API calls are equivalent.
How do computers represent API calls
At its core, API calls are a type of function invocation. The question on how to represent a program dates back to the 1960s when Donald Knuth (the inventor of TEX) introduced Abstract Syntax Trees (AST)[1]. Since then, ASTs have been a powerful program representation for checking programs are equivalent and applying automatic program optimizations. Compiler designers can define rewrites on ASTs and be confident program correctness is not impacted by writing equivalence proofs [2]. We illustrate this process with desugaring default arguments. Suppose the `pretrained` argument is by default true. Then, `API_Function(my_model, pretrained=True)` and `API_Function(my_model)` are intuitively equivalent. However, the computer sees two strings of characters that are clearly different. By representing as an AST, we can apply an equivalence preserving rewrite that populates the tree with default arguments. Now, it’s easy to check the ASTs representing the function calls are equivalent implying the original function calls are equivalent.
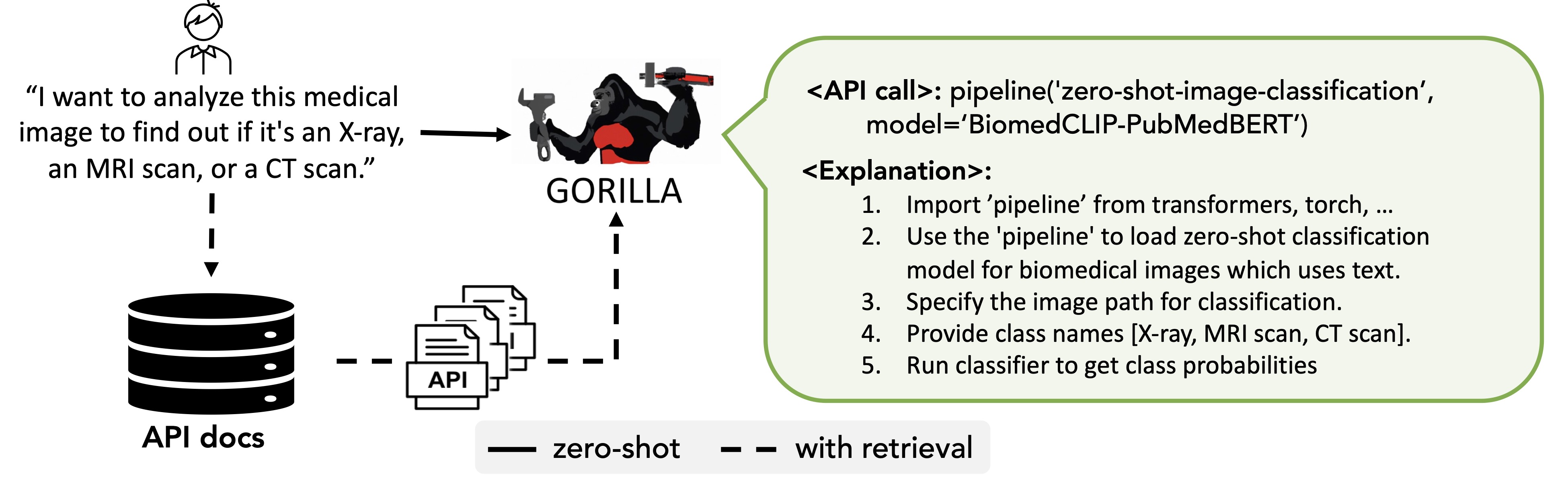
Gorilla, can be used for inference in two modes: zero-shot and with retrieval. In zero-shot, the prompt is directly fed to the Gorilla LLM model. In retrieval mode, the retriever first retrieves the most up-to-date API documentation stored in APIZoo.
Measuring Hallucinations in LLMs
Any individual API call can be parsed or expressed uniquely as an abstract syntax tree (AST). In the AST, nodes represent each argument or class function. For instance, the image below shows a generated AST for loading `ResNet50` with `torch.hub.load`: ```torch.hub.load(‘pytorch/vision:v0.10.0’, ‘ResNet50’, pretrained=True)``` We note however that `pretrained` is an auxiliary argument not crucial to the API validity. We can check for hallucinations by carefully curating all base API function calls such as `torch.hub.load(‘pytorch/vision:v0.10.0’, ‘ResNet50’)`. These base API function calls can be standardized to ```API_name(API_arg1, API_arg2, ..., API_argk)``` Standardization allows us to check that generated AST invokes one of the base API function calls. Particularly for deep learning APIs strings/paths are used to represent models and repositories. This free-text format lowers the friction for adding new models, but limits the program analysis that can be done. For deep learning APIs, a key validity check is that the model exists in the repository. In the case of torch.hub API which supports a list of 94 models, we check if the API call invokes one of the existing models. The AST subtree matching easily checks if the model and repository are a valid pair in the curated list of API calls. ASTs are a standard yet powerful structured representation that allows us to do subtree matching to efficiently check if an API call is hallucinated.

Examples of API calls. In this example, for the given prompt GPT-4 presents a model that doesn't exist, and Claude picks an incorrect library. In contrast, our Gorilla model can identify the task correctly and suggest a fully-qualified API call.
Reality Bytes: When LLMs See Things That Aren't There
Hallucination is the center of discussions for all things LLMs. In the context of API generation, hallucination can be defined as the model generating API calls that do not exist. An LLM generation can be in-accurate or it could be hallucinated. One does not mean the other. For example, if the user asks for a classifier for medical images, if the model generates a Stripe API call for a image classifier - it is hallucination, since it doesn't exist! On the other hand, if the model recommends to use the Stripe API for checking your balance, it is an incorrect usage of the API, but at least not made up (noh-hallucinated). In our blog we describe Gorilla's innovative approach of using Abstract Syntax Trees (ASTs) to measure hallucination of the generated API calls. Though not generalizable to all tasks, to the best of our knowledge, Gorilla is the first to measure and quantify hallucination for LLM generations!
Gorilla Hallucinations
Good retrievers reduce hallucinations. The outlined AST subtree matching method highlights the importance of quality retrieval in reducing hallucinations. We evaluate Gorilla on three retrieval settings: 1) BM-25, a classic keyword retriever, 2) GPT-Index, a nearest neighbor search over gpt document embeddings, and 3) Oracle, ground truth. Each retriever appends the documentation of one API call to the context. With the improvement in retrieval accuracy from BM-25 to GPT-index we see Gorilla virtually eliminate hallucinations. GPT-4 also shows strong benefit from retriever quality leading to a 91% reduction to hallucination. Remarkably, GPT-4 benefits more from retrieval than Claude suggesting models can be optimized to make better use of retrieved documentation! Learn more about our retriever-augmented generation here.
Takeaways
Language models just like humans will hallucinate and non-maliciously make false statements. Though our focus is on LLM APIs, to the best of our knowledge, Gorilla is the first to measure and quantify hallucination for LLM generations! “Though our focus is on LLM APIs, to the best of our knowledge, Gorilla is the first to measure and quantify hallucination for LLM generations! ” These are some takeaways on measuring hallucinations:
- Use ASTs to measure API hallucination. For LLM APIs, we introduce a novel approach to check for hallucinations using subtree matching of Abstract Syntax Trees (AST).Retrievers reduce hallucinations. We find that improving the retriever reduces hallucinations!
- The first step in solving a problem is recognizing there is one. We are excited by the potential of automatically fixing and self-healing when API calls are hallucinated. Just as you would ask if grandmother meant to suggest cutting the strawberries, we envision future language model powered API calls will ask targeted clarifying questions.
We hope you enjoyed this blog post. We would love to hear from you on Discord, Twitter (#GorillaLLM), and GitHub.
If you would like to cite Gorilla:
@inproceedings{patil2024gorilla,
title={Gorilla: Large Language Model Connected with Massive APIs},
author={Patil, Shishir G. and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E.},
year={2024},
journal={Advances in Neural Information Processing Systems}
}