🦍 Gorilla: Large Language Model Connected with Massive APIs
Blog 3: Retrieval Aware Training (RAT)
Retriever-Aware Training (RAT): Are LLMs memorizing or understanding?
Pretrained Language Models (LLMs) need instruction tuning to better align with human incentives. These methods both improve the model’s behavior and accuracy when they are trying to answer questions for a specific domain. However, traditional instruction tuning has limitations regarding adaptability, dependency on the in-context examples, and the potential to hallucinate. We introduce "retriever-aware training," a new methodology that holds the promise of addressing some of these challenges. Let's dive into the details of that.
The Drawbacks of Traditional Instruction Tuning
At its core, instruction tuning allows LLMs to generate responses based on specific instructions embedded within the prompts. However, this approach has its limitations:
- Limited Adaptability: Traditional LLMs may struggle when faced with real-time changes or updates in the information. This can be particularly concerning when using evolving data sources, such as API documentation.
- Dependence on In-Context Learning: Instruction tuning relies heavily on in-context learning, which can be restrictive. Without the ability to pivot based on fresh or updated data, the model might produce outdated or inaccurate outputs.
- Potential for Hallucination: One of the significant challenges with LLMs is their tendency to "hallucinate" or generate incorrect or unrelated information. Traditional tuning methods have been known to exacerbate this issue.
Embracing Retriever-Aware Training
With the above challenges in mind, retriever-aware training was introduced.
The principle behind this method is to append additional supporting documentation to the user's prompt,
such as "Use this API documentation for reference:
A free lunch for RAT?
However, the promise of retriever-aware training is not fully utilized yet in reality. This is mainly because the accuracy of the retriever is not good enough. In other words, the recall for the retriever has become a bottleneck for the final performance of the LLM. Imagine the model would easily get confused if it got the question to “look up whether in Berkeley” but with the supporting documents of “biography of Albert Einstein”. Thus, balancing between the recall of the retriever and the frequency of updating LLMs is a choice to make.
Wrapping Up As with all innovations, retriever-aware training comes with its set of pros and cons. But its introduction marks an exciting shift towards creating LLMs that are more adaptable, accurate, and less prone to errors. As we continue to refine this methodology, there's no doubt that the future of LLM training is brimming with potential.
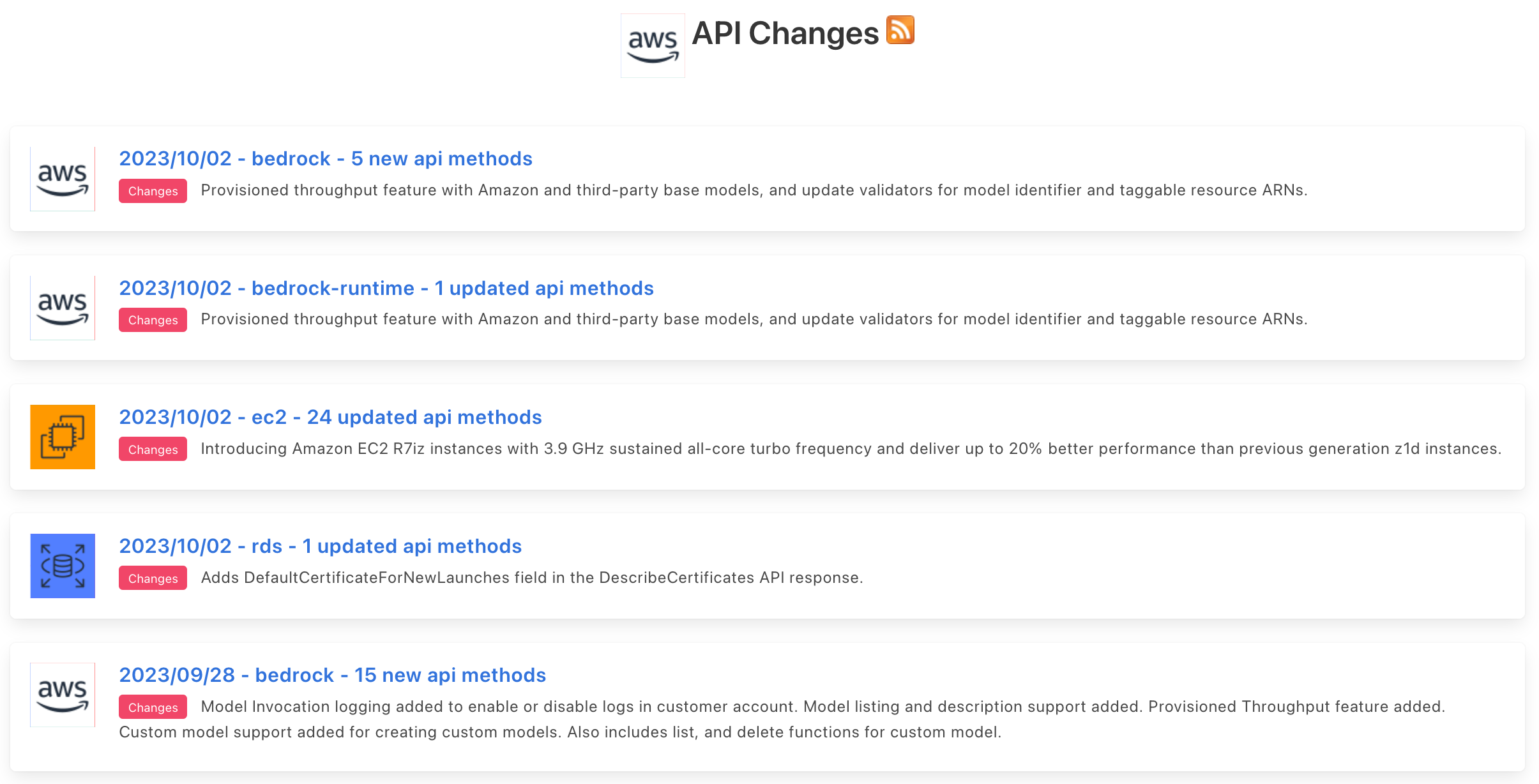
APIs evolve frequently! For example, there were 31 API modifications for AWS APIs just yesterday.
Keeping up with frequently evolving APIs
APIs are known to evolve frequently - more frequently than it is possible to re-train LLMs. So, how can LLMs keep up with this, and not serve the user out-lawed APIs? To handle this, Gorilla, can be used for inference in two modes: zero-shot and with retrieval. In zero-shot, during inference, user provides the prompt in natural language. This can be for a simple task (e.g, "I would like to identify the objects in an image"), or you can specify a vague goal, (e.g, "I am going to the zoo, and would like to track animals"). This prompt (with NO further prompt tuning) is fed to the Gorilla LLM model which then returns the API call that will help in accomplishing the task and/or goal. In retrieval mode, the retriever first retrieves the most up-to-date API documentation stored in APIZoo, an API Database for LLMs. Before being sent to Gorilla, the API documentation is concatenated to the user prompt along with the message "Use this API documentation for reference:" The output of Gorilla is an API to be invoked. The retriever aware inference mode, enables Gorilla to be robust to frequent changes in APIs! We have open-sourced our APIZoo, and welcome contributions from the community!
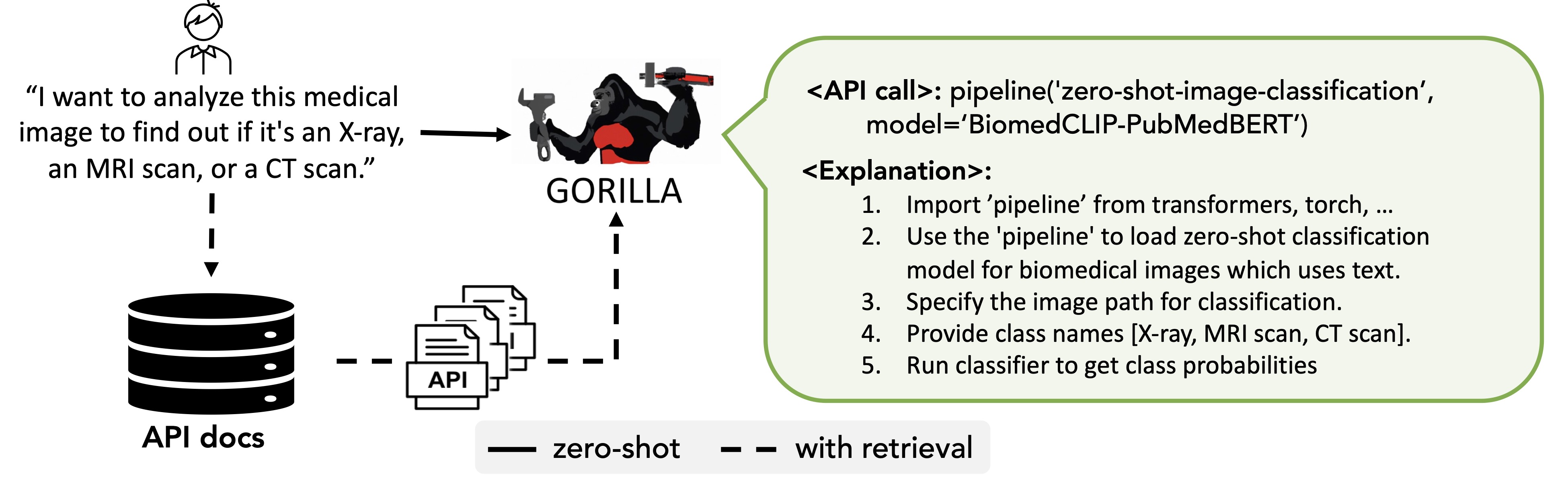
Gorilla, can be used for inference in two modes: zero-shot and with retrieval. In zero-shot, the prompt is directly fed to the Gorilla LLM model. In retrieval mode, the retriever first retrieves the most up-to-date API documentation stored in APIZoo.
We hope you enjoyed this blog post. We would love to hear from you on Discord, Twitter (#GorillaLLM), and GitHub.
If you would like to cite Gorilla:
@inproceedings{patil2024gorilla,
title={Gorilla: Large Language Model Connected with Massive APIs},
author={Patil, Shishir G. and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E.},
year={2024},
journal={Advances in Neural Information Processing Systems}
}