🦍 Gorilla: Large Language Model Connected with Massive APIs
BFCL V4: Memory
BFCL V4 • Agentic
Part 2: Evaluating Tool Calling for Memory
With function-calling being the building blocks of Agents, the Berkeley Function-Calling Leaderboard (BFCL) V4 presents a holistic agentic evaluation for LLMs. BFCL V4 Agentic includes web search (part‑1), memory (detailed in this blog), and format sensitivity (part‑3). Together, the ability to web search, read and write from memory, and the ability to invoke functions in different languages present the building blocks for the exciting and extremely challenging avenues that power agentic LLMs today—from deep research to agents for coding and law.
If you're new to function calling, be sure to check out our earlier blog posts for more background. In BFCL V1, we introduced expert‑curated single‑turn, simple, parallel, and multiple function calling. BFCL V2 introduced community–hobbyists and enterprise–contributed functions. BFCL V3 introduced multi‑turn and multi‑step function calling that let models interact with the user, including the ability to go back‑and‑forth asking clarifying questions and refining the approach. Throughout, BFCL relies on AST (Abstract Syntax Tree)‑based, or state‑transition based verification ensuring determinism and minimal fluctuations as you evaluate your models and applications.
Quick Links:
- BFCL Leaderboard: Website
- BFCL Dataset: HuggingFace Dataset 🤗
- Reproducibility: Github Code
- BFCL v1: Simple, Parallel, and Multiple Function Call eval with AST
- BFCL v2: Enterprise and OSS-contributed Live Data
- BFCL v3: Multi-Turn & Multi-Step Function Call Evaluation
- BFCL v4 Agentic: Part 1 Web Search
- BFCL v4 Agentic: Part 2 Memory
- BFCL v4 Agentic: Part 3 Format Sensitivity
In our past releases, we are encouraged by the community's deep appreciation of the insights across different models. So, this time we have divided our BFCL V4 release blogs into three parts to address the technical complexities, and more importantly share many more interesting insights.
1. Introduction
Humans naturally recall past conversations, preferences, and relevant details, enabling continuity and personalization in ongoing interactions. Granting LLM-based agents the capacity to remember and build upon prior exchanges is therefore pivotal for creating richer, more context-aware user experiences. For instance, ChatGPT's memory system enhances personalized chatbot experiences by remembering user preferences and previous interactions, both through explicit memories saved by the user and by referencing prior conversations. This allows the model to tailor suggestions, maintain natural continuity, and adapt its responses over time, all while giving users control over what's remembered.
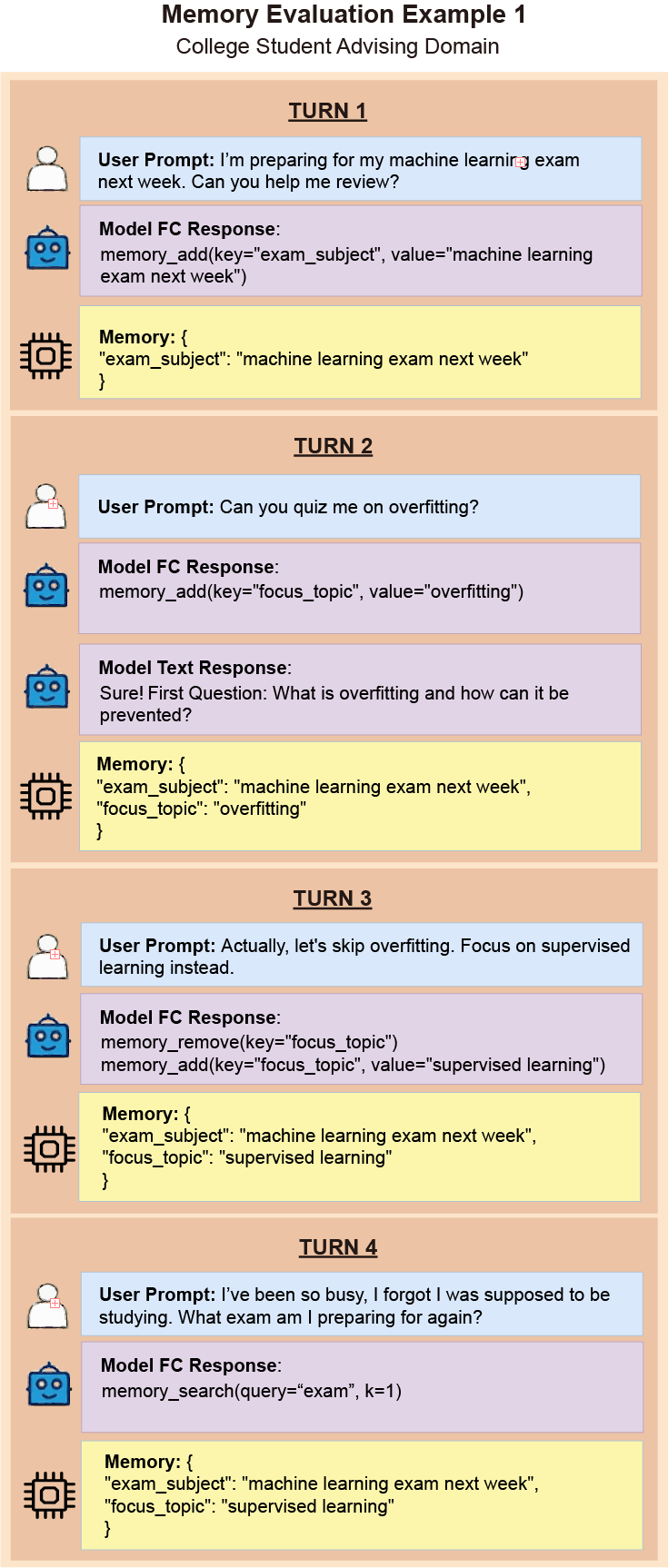
To enable this deeper level of agentic functionality, BFCL v4 provides structured memory testing backends. These systems allow agents to store and retrieve information during a conversation by using a set of dedicated memory tools. With these capabilities, models can keep track of important details, reference past interactions, and provide a much more seamless, context-aware experience for users. In designing the memory dataset, we focused on five practical domains: customer support, healthcare, student advising, finance, and personal productivity. Each domain features complex, multi-turn conversations designed to stress‑test a model's ability to maintain conversational coherence, recall previously stated facts, and continuously adapt as the context evolves.
We have divided our BFCL v4 release blogs into two parts to address the technical complexities, and more importantly share the interesting insights. This blog BFCL V4 part-1 talks about Web search, and here we talk about Memory.
2. Memory Dataset
To rigorously evaluate the memory capabilities introduced in BFCL v4, we designed a comprehensive dataset that captures realistic scenarios where memory use is critical. This dataset emphasizes practical applications, thorough testing, and real-world relevance across multiple domains. The dataset consists of 3 components:
-
Context: Multi-turn conversations that reflect
realistic user-agent interactions and evolving needs over time.
- Curation: We selected five high-impact domains, illustrated below, based on where AI assistants are already used or show strong potential. We drafted the conversations by researching publicly available conversations in each domain and manually crafting realistic, multi-turn dialogues.
-
Tool Integration: A set of tools that enable
the model to communicate with the memory backends.
- Curation: Each conversation was paired with custom-made function-calling APIs for memory operations covering basic means of handling memory including adding, removing, searching, and clearing memory. These APIs simulate how LLMs interact with structured memory backends in real-world settings.
-
Question: After context sessions, we created
targeted follow-up questions to test whether the model could
retrieve specific information only available via memory,
mimicking real users revisiting past topics or checking on prior
details.
- Curation: Each question was manually written to align with prior user multi-turn conversations, requiring models to retrieve specific facts via memory APIs.
The below are the chosen 5 domains:
- College Student Advising: Tests whether models can retain academic and personal context to support short and long‑term student advising.
- Customer Support: Evaluates continuity in handling user issues, preferences, and prior interactions for effective service.
- Personal To‑Do List: Assesses the model's ability to manage evolving daily tasks and routines with consistent recall.
- Healthcare Patient: Measures accuracy in tracking medical histories, lifestyle changes, and ongoing treatment plans.
- Finance Managing Director: Examines memory use in complex financial advising scenarios involving long‑term strategy.

3. Memory Backend Implementation
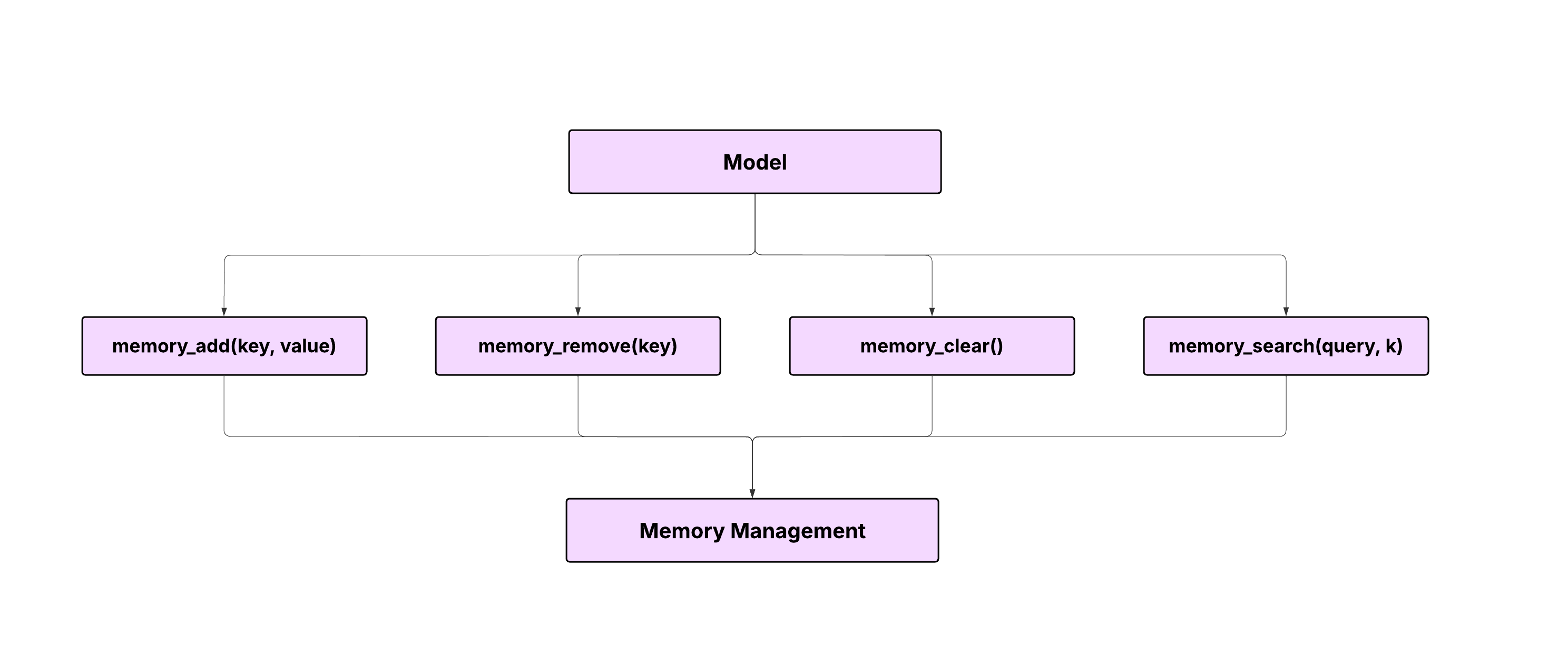
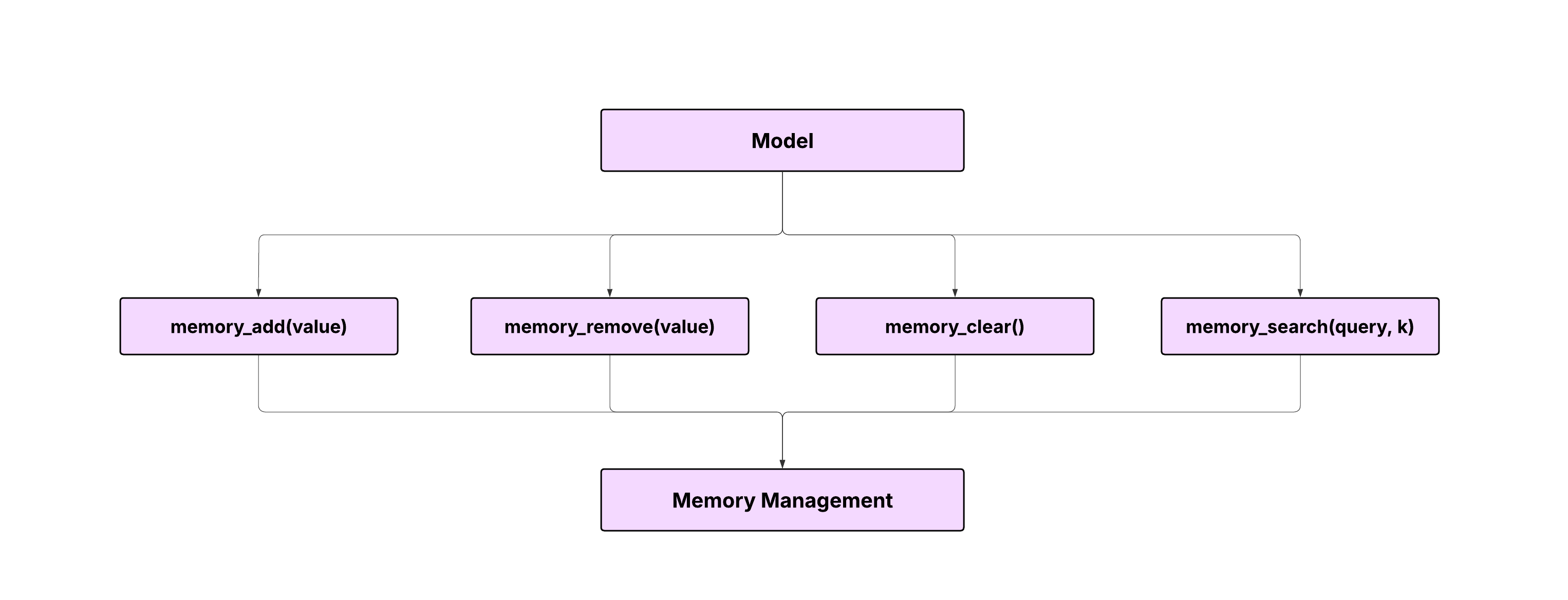
BFCL V4's memory backend enables a model to store, retrieve, and manage context. We've implemented three distinct memory architectures: Key Value Store, Vector Store, and Recursive Summarization. Each memory backend features core and archival memory segments as explained above, inspired from existing agents with memory such as MemGPT, Mem0, and Memory for Llama-Index. The architectures evaluate diverse memory behaviors, from precise key‑based recall to semantic retrieval and narrative summarization.
| Key Value Store | Vector Store | Recursive Summarization | |
|---|---|---|---|
| Definition | A structured memory that stores data as key value pairs for exact lookups. | A semantic memory that stores vector embeddings for similarity‑based retrieval. | A running text buffer that accumulates and compresses conversation history. |
| API Interface |
memory_add()
memory_remove()
memory_clear()
memory_search()
|
memory_add()
memory_remove()
memory_clear()
memory_search()
|
memory_append()
memory_update()
memory_replace()
memory_clear()
memory_retrieve()
|
| Search Method | BM25+ keyword search over keys | Embedding-based nearest neighbor search using cosine similarity | No search; model must recall from condensed buffer via summarization |
| Cost | Low: Fast and deterministic, relies on structured key naming | Medium: Flexible retrieval with moderate overhead due to search | High: Model‑managed compression over long text buffers |
| Best Use Case | Best for exact, structured recall where information is saved under clear, consistent keys. | Best for retrieving semantically similar content when wording varies. | Best for maintaining a running narrative where information is stored as free-form text. |
3.1 Key Value Store
A classic dictionary-style memory for interpretable, structured recall.
Entry format: (key, value) where keys
follow strict snake_case naming (no spaces, lowercase).
API:
memory_add(key, value)memory_remove(key)memory_clear()memory_search(query, k) # BM25+ over keys
Design note. We favoured an in-memory store over SQLite/TinyDB for speed, transparency, and deterministic snapshot-and-reload during benchmarking.
3.2 Vector Store
A similarity-based memory that feels closer to human "gist" recall.
-
Embedding model:
all-MiniLM-L6-v2 - Index: FAISS (in-memory)
-
Usage:
memory_search(query, k)embeds the query and returns the top-k nearest vectors.
3. Recursive Summarization
A single, ever-growing text buffer: think "running diary".
API:
memory_append(text)memory_update(text)memory_replace(old, new)memory_clear()memory_retrieve()Limit: 10000 characters (forces compression).
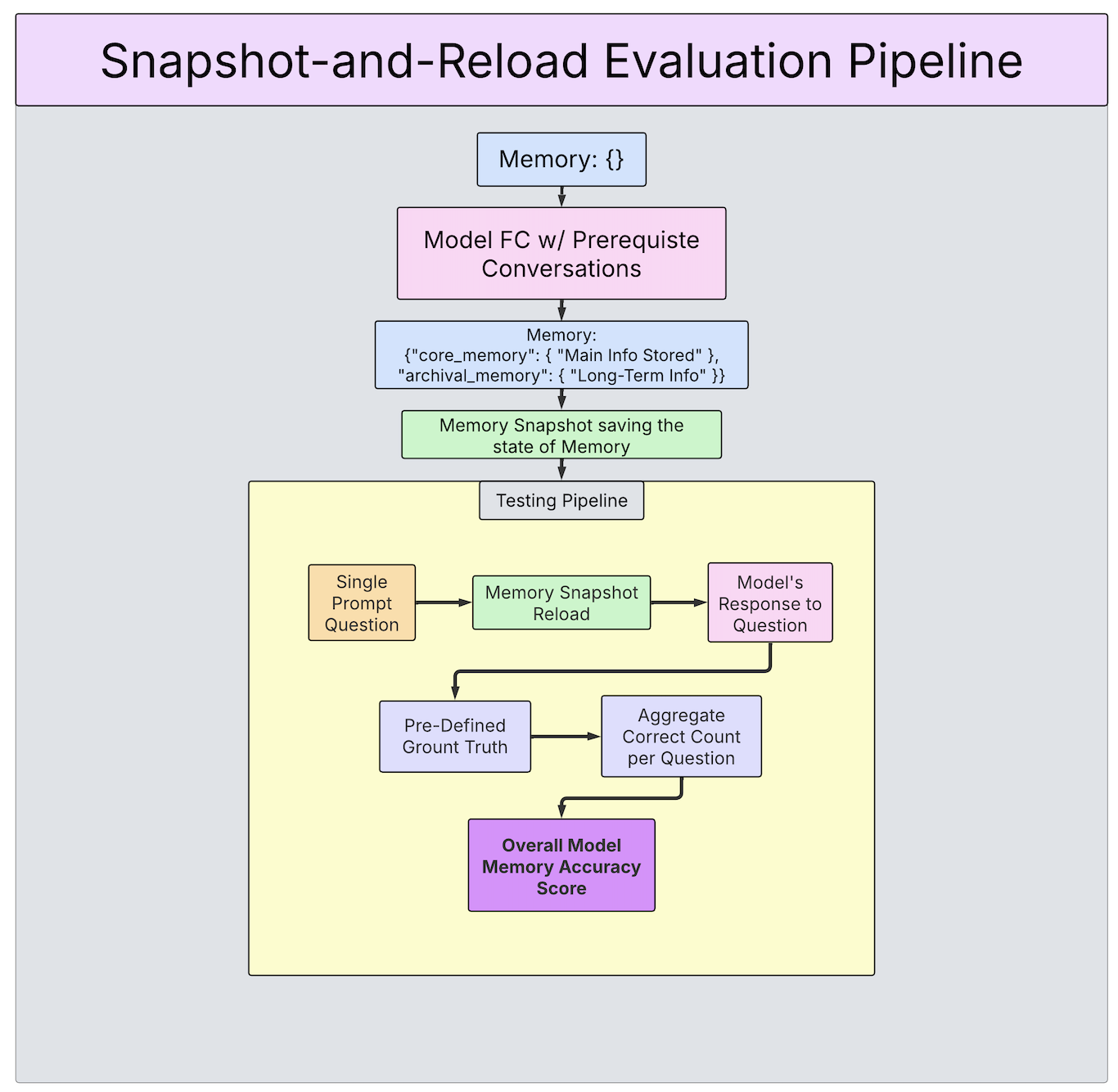
4. Memory Pipeline Flow: Snapshot-and-Reload
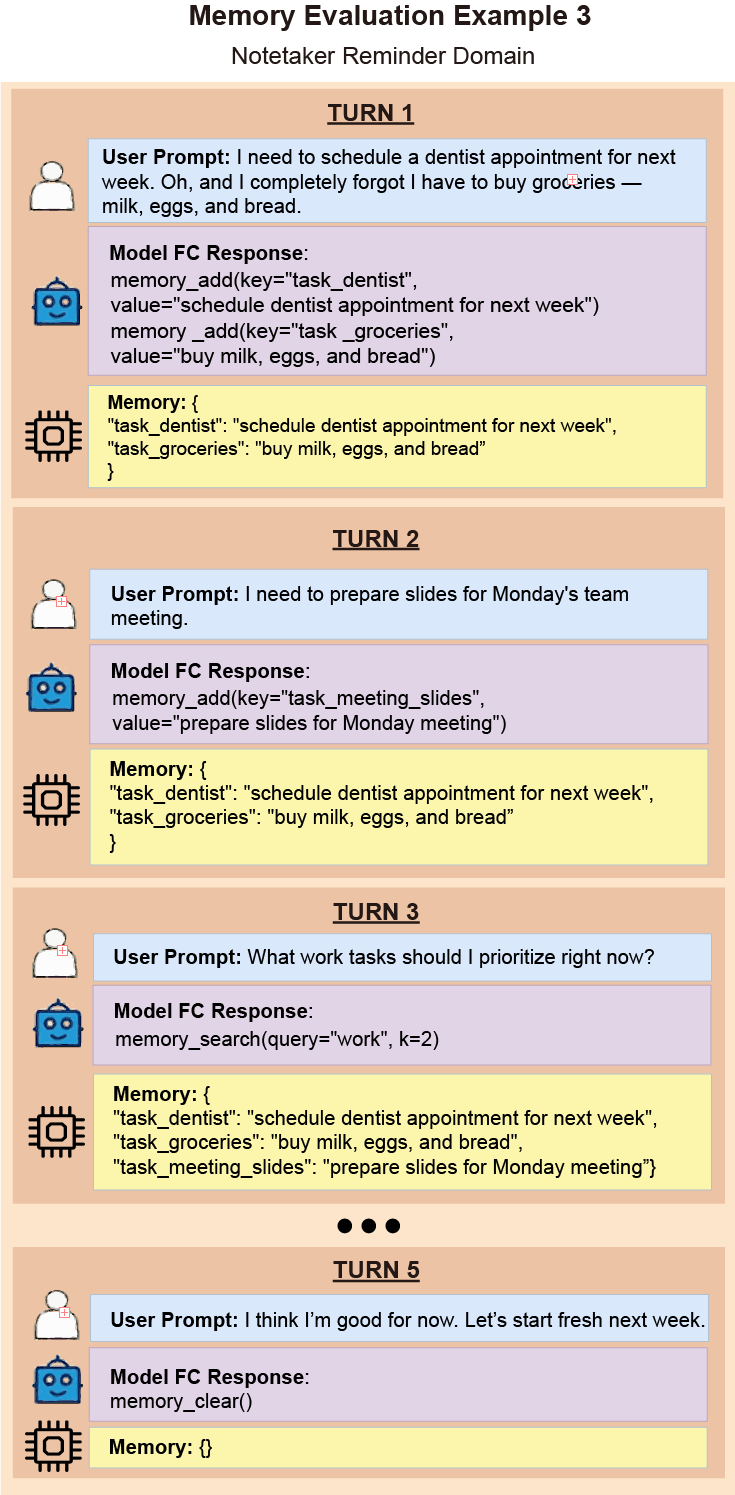
Each domain-specific dataset contains three parts:
-
Prefilling Memory with Prerequisite Conversations
This phase comprises multiple conversational sessions, each covering distinct subtopics within realistic dialogues. For example, a college student might discuss coursework in one session, extracurricular activities in another, and career advice later.
- Initially, the memory starts empty. As conversations unfold, the model populates the memory backend using provided APIs.
- After each session, a memory snapshot—a serialized state—is saved to preserve the memory state across sessions.
- Before starting each new session, the relevant snapshot is reloaded to ensure continuity.
-
Evaluating Questions on Prefilled Memory
During the evaluation phase, the final memory snapshot is loaded, and the model is presented with targeted follow-up questions (e.g., "Where am I traveling next weekend for a small freelance gig?").
- Each evaluation question begins with the same snapshot to maintain isolation between questions.
- The primary goal is assessing memory retrieval: the model must explicitly query the memory backend rather than relying on prior dialogue context.
-
Verifier
- Responses are evaluated against ground truth to determine correctness, verifying that models accurately store and retrieve relevant information via memory tools.
- No dialogue history is provided during evaluation to mimic real-world assistant behavior.
- We vary question phrasing, topic progression, and style to ensure models rely on explicit memory queries rather than recent conversational context. This method robustly tests genuine memory management capabilities over time.
A diagram of the entire process is provided below:
5. Insights
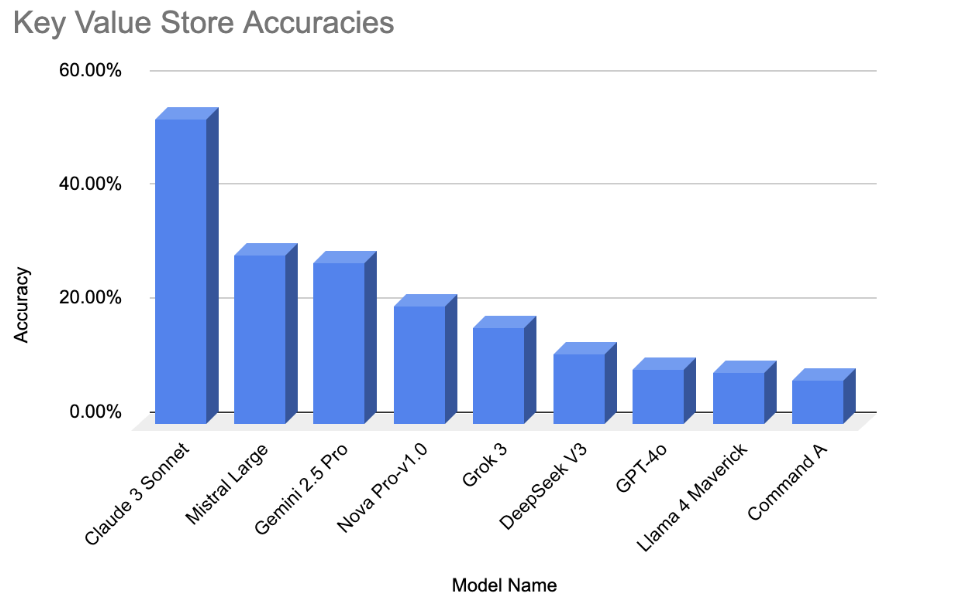
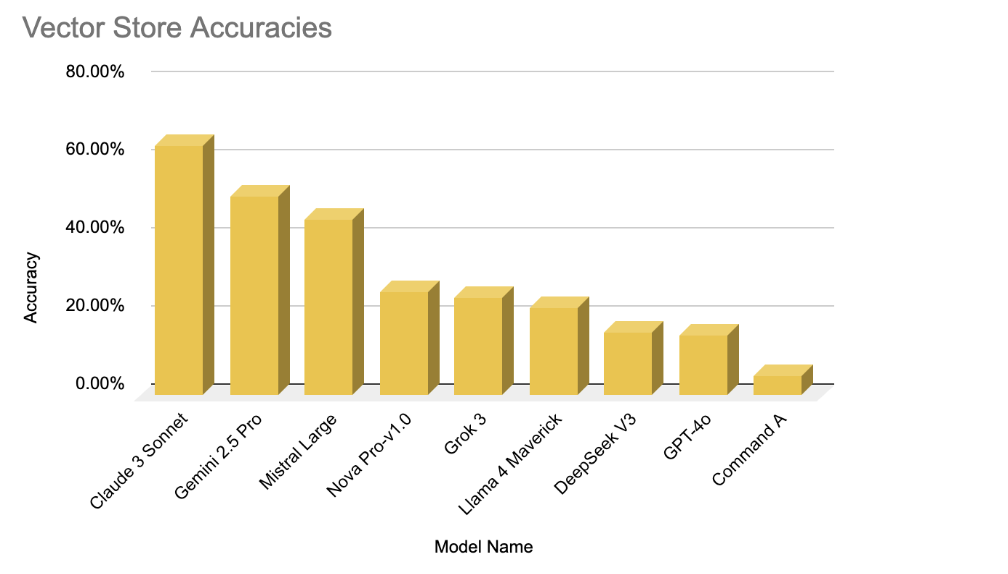
Our memory evaluation framework identified three distinct behavioral patterns in how LLMs store and retrieve user information. These findings emerge from model accuracy metrics across three memory backends, namely Key Value Store, Vector Store, and Recursive Summarization. Overall, models that demonstrated accurate memory use exhibited consistent alignment between user queries and stored memory entries. In contrast, models with low accuracy frequently struggled due to failed retrievals, excessive deletion, or semantic mismatches.
5.1 Key Success Patterns
From our evaluation of 150+ questions, we identified three dominant memory behaviors. Each behavior reveals how models store, retrieve and balance information across core and archival memory.
1. Complementary Core and Archival Use: High performing models displayed a clear separation of concerns across memory types. Specifically, core memory that was used for persistent, identity facts such as "user_name", or "user_major", were successful. Archival memory that was used to store dynamic details such as recent orders or travel updates led to successful retrieval.
2. Archival-Only Reliance with Sparse Core Use: Some models avoided core memory entirely and instead relied exclusively on archival memory to answer user queries. This approach worked well when queries closely mirrored more descriptive content.
3. Contextual Consolidation Across Turns: Certain models succeeded by summarizing or grouping related facts across dialogue turns. This enabled accurate recall even for abstract or indirect queries as it efficiently stored the most important details across a user conversation.
5.2 Notable Failure Pattern: Aggressive Memory Deletion
A notable pattern was models' aggressive removal of memory entries, even when memory storage was not constrained. Models frequently prioritized newly deemed urgent information, discarding previously stored details prematurely. Consequently, when queried later, these models failed to recall information they had recently purged, undermining continuity. This behavior suggests that models tend to overly prioritize recent, dense data over historically significant yet precise information, potentially weakening long-term conversational coherence.
5.3 Backend Trade‑offs
Our evaluation also reveals trade-offs among memory backend implementations:
Key Value Stores:
Top Model: Claude 3 Sonnet – 53.55%
Lowest Model: Command A – 7.74%
Difference: 45.81 Percentage Points
KV Store excelled at exact, deterministic lookups, particularly for structured identifiers like names, metrics, or static preferences. However, they struggled when user queries were rephrased or semantically drifted from the original key. For instance, multiple models failed to retrieve correct responses when the query deviated slightly from stored phrasing, despite memory presence.
Vector Stores:
Top Model: Claude 3 Sonnet – 63.87%
Lowest Model: Command A – 5.16%
Difference: 58.71 Percentage Points
Vector store retrieval supported semantic generalization, enabling models to locate related concepts even when the user used new or abstract phrasing. However, this flexibility came at a cost: hallucinated answers were common. For example, some models returned plausible-sounding but incorrect memory entries due to weak relevance scoring.
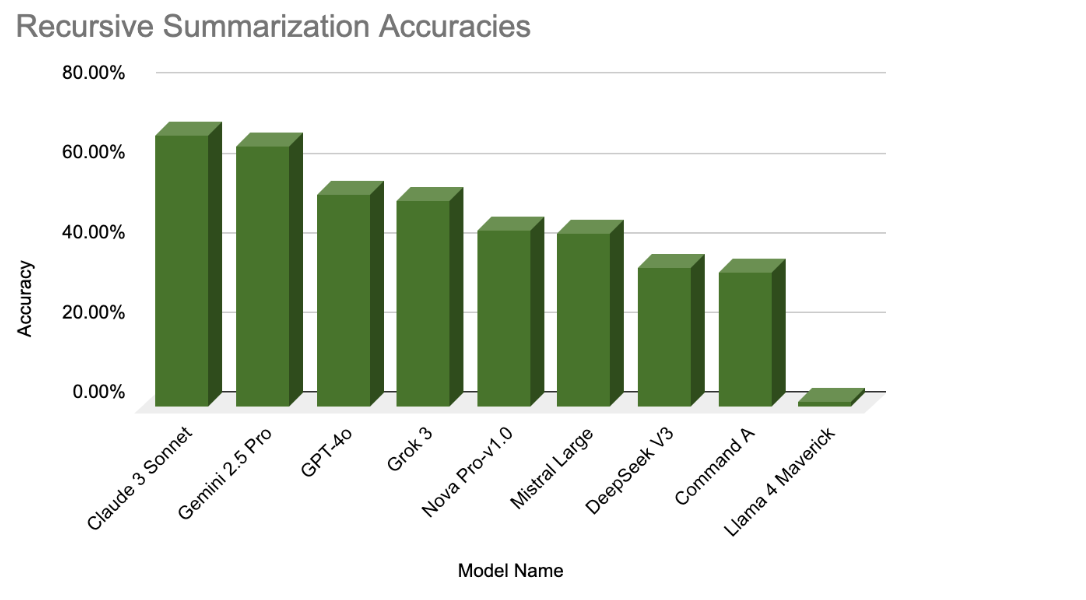
Recursive Summarization Stores
Top Model: Claude 3 Sonnet – 67.74%
Lowest Model: Lama 4 Maverick – 1.29%
Difference: 66.45 Percentage Points
Recursive summarization yielded the highest peak performance, especially for models like Claude and Gemini. These models maintained a coherent narrative across turns, supporting long-term context integration. However, they sometimes over-summarized, leading to the loss of precise details needed for accurate recall.
6. Specific Failure Examples
To understand the failure cases, we include the following for each scenario:
Relevant Prerequisite Conversation: This is from the user's conversation and is given to the model to decide what to do with the information. The model uses explicit function calls such as memory_retrieve, core_memory_add, and memory_remove to control its memory in a way the model sees fit.
User Question: This is the question that is asked from the "user" to the model and tests whether the model is able to retrieve the answer to the question accurately.
Model Response: This is two fold:
- Answer: The model's response to the user question
- Context: What information the model was able to retrieve via API call to answer the question
Ground Truth: The expected correct answer, used as the reference to evaluate whether the model's response is accurate.
Model Memory Snapshot: Shows the relevant part of what the model's self-managed memory looks like. If the answer is not found in memory, the reason for why it isn't found is specified here instead.
Scenario 1 (Overwriting Core Information in Urgent Contexts)
Relevant Pre-Req Conversation:
"Work-related: Finalize quarterly budget. Review vendor contract before signing. Finish security compliance training module."
User Question:
I completely forgot. What training module did I have to finish?
Model Response:
{
'answer': 'You need to prep materials this weekend for Monday.',
'context': 'This information was retrieved from your archival memory under the key "training_session_prep".'
}
Ground Truth:
["Security Compliance"]
Model Memory Snapshot:
The model had just deleted this item using memory_remove.Scenario 2 (Failure to Capture & Retrieve Nuanced Intent)
Relevant Pre-Req Conversation:
"On the grad school front: part of me is really intrigued by the idea of continuing my research in immersive analytics or even branching into human-computer interaction for large datasets."
User Question:
If I do grad school, what do I want to do research in?
Model Response:
{
'answer': 'You might want to consider research in areas like quantum computing, machine learning applications, or the intersection of AI and philosophy.',
'context': 'Based on your current interests and coursework, you are deeply engaged in quantum computing, machine learning, and the philosophical implications of AI.'
}
Ground Truth:
["Immersive analytics", "Human computer interaction"]
Model Memory Snapshot:
"archival_memory": {
"next_id": 44,
"store": {
"36": "User has formed a friendly circle at the gym [...] interests in machine learning and hardware acceleration."
}
}Scenario 3 (Hallucination During Open‑Ended Recall)
Relevant Pre-Req Conversation:
"My lattes are consistently delicious, and I'm sure they could be even better with the right steam wand."
User Question:
What could make my lattes even better?
Model Response:
{
'answer': 'To enhance your lattes, consider experimenting with high-quality espresso beans, frothing techniques [...] properly calibrated.',
'context': 'This answer is based on general best practices for improving lattes'
}
Ground Truth:
["steam wand"]
Model Memory Snapshot:
(memory contents unrelated to coffee steam wand)We hope you enjoyed this blog post. We would love to hear from you on Discord, Twitter (#GorillaLLM), and GitHub.
If you would like to cite BFCL:
@inproceedings{patil2025bfcl,
title={The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models},
author={Patil, Shishir G. and Mao, Huanzhi and Cheng-Jie Ji, Charlie and Yan, Fanjia and Suresh, Vishnu and Stoica, Ion and E. Gonzalez, Joseph},
booktitle={Forty-second International Conference on Machine Learning},
year={2025},
}