🦍 RAFT: Adapting Language Model to Domain Specific RAG
Tianjun Zhang Shishir G. Patil Kai Wen Naman Jain Sheng Shen Matei Zaharia Ion Stoica Joseph E. Gonzalez
![]()
When integrating Large Language Models (LLMs) into various applications, it often becomes necessary to incorporate new information, such as domain-specific knowledge or proprietary data, through techniques like retrieval-augmented generation (RAG)-based prompting or fine-tuning. However, the challenge lies in determining the most effective method for instilling this new knowledge into the model. In our latest blog, we introduce Retrieval Augmented Fine Tuning (RAFT), a straightforward and powerful fine-tuning recipe to enhance the model's performance in answering questions within specific domains in an "open-book" setting. Open-book refers to the paradigm, where the model can refer to documents to answer the question. RAFT operates by training the model to disregard any retrieved documents that do not contribute to answering a given question, thereby eliminating distractions. This is achieved by accurately identifying and quoting the relevant segments from helpful documents to address the question at hand. Moreover, RAFT's use of a chain-of-thought-style response further refines the model's reasoning abilities. When applied to domain-specific RAG, RAFT consistently improves performance across various datasets, including PubMed, HotpotQA, and Gorilla, offering a valuable post-training enhancement for pre-trained LLMs with domain-specific RAG capabilities. In our previous blog about RAT (Retriever Aware Training), we explored optimization strategies for models interacting with APIs. RAFT builds on top of RAT, and generalizes beyond APIs for RAG applications.
The RAFT model is trained on top of the base model Llama2-7B from Meta and on Microsoft AI Studio. We provide a short tutorial on how to train your own RAFT model for RAG applications. For more details about RAFT please refer to our paper and Microsoft-Meta blog.
Analogy: How to prepare a LLM for an Exam? 📝
RAFT is a general recipe to finetune a pretrained LLM to your domain-specific RAG settings.
This is a common scenario where you want your LLM to answer questions grounded on a set of documents, for e.g., private files in an enterprise.
Such a setting is different from the general RAG where the LLM does not know which domain (of documents) it will be tested on.
To better illustrate this setting, let's draw an analogy between deploying and using an LLM with the real-world setting of prepararing for an exam.
Closed-Book Exam
A closed book exam often refers to the scenario where the LLMs do not have access to any additional documents or references to answer the questions during the exam.
For LLMs, this is equivalent to the scenario, for example, in which the LLM is used as a chatbot. In this scenario the LLM draws from the knowledge baked in during pre-training and supervised-finetuning to respond to the users' prompt.
Open-Book Exam
In contrast, we liken the open-book exam setting to the scenario in which the LLM can refer to external sources of information (e.g., a website or a book chapter).
In such scenarios, typically, the LLM is paired with retriever which retrieves k documents (or specific segments of the document) which are appended to the users' prompt. It is only through these documents retrieved that the LLM gains access to new knowledge.
As a result, we argue that the LLM's performance in these settings, where it is trained as a general-purpose LLM is largely dependent on the quality of the retriever and how accurately the retriever can identify the most relevant piece of information.
RAFT
RAFT focuses on a narrower but increasingly popular domain than the general open book exam, called the domain-specific open-book exam. In domain-specific open book exam, we know a priori the domain in which the LLM will be tested --- used for inference. The LLM can respond to the users' prompt using use any and all information from this specific domain, which it has been fine-tuned on.
Examples of domain specific examples include enterprise documents, latest news, code repositories belonging to an organization, etc.
In all these scenarios, the LLM will be used to respond to the questions, whose answers can be found within a collection of documents (a small practical domain). The retrieval technique itself has little to no-impact on the mechanism (though it may impact the accuracy).
This paper mainly studies this, domain-specific open-book setting and how to adapt a pretrained LLM to this specific domain, including how to make it more robust to a varying number of retrieved documents and distractors.
RAFT is a general recipe to finetune a pretrained LLM to your domain-specific RAG settings. This is a common scenario where you want your LLM to answer questions grounded on a set of documents, for e.g., private files in an enterprise. Such a setting is different from the general RAG where the LLM does not know which domain (of documents) it will be tested on. To better illustrate this setting, let's draw an analogy between deploying and using an LLM with the real-world setting of prepararing for an exam.
Closed-Book Exam A closed book exam often refers to the scenario where the LLMs do not have access to any additional documents or references to answer the questions during the exam. For LLMs, this is equivalent to the scenario, for example, in which the LLM is used as a chatbot. In this scenario the LLM draws from the knowledge baked in during pre-training and supervised-finetuning to respond to the users' prompt.
Open-Book Exam In contrast, we liken the open-book exam setting to the scenario in which the LLM can refer to external sources of information (e.g., a website or a book chapter). In such scenarios, typically, the LLM is paired with retriever which retrieves k documents (or specific segments of the document) which are appended to the users' prompt. It is only through these documents retrieved that the LLM gains access to new knowledge. As a result, we argue that the LLM's performance in these settings, where it is trained as a general-purpose LLM is largely dependent on the quality of the retriever and how accurately the retriever can identify the most relevant piece of information.
RAFT RAFT focuses on a narrower but increasingly popular domain than the general open book exam, called the domain-specific open-book exam. In domain-specific open book exam, we know a priori the domain in which the LLM will be tested --- used for inference. The LLM can respond to the users' prompt using use any and all information from this specific domain, which it has been fine-tuned on. Examples of domain specific examples include enterprise documents, latest news, code repositories belonging to an organization, etc. In all these scenarios, the LLM will be used to respond to the questions, whose answers can be found within a collection of documents (a small practical domain). The retrieval technique itself has little to no-impact on the mechanism (though it may impact the accuracy). This paper mainly studies this, domain-specific open-book setting and how to adapt a pretrained LLM to this specific domain, including how to make it more robust to a varying number of retrieved documents and distractors.
 How to prepare a LLM for an Exam? Closed-Book vs. Open-Book vs. RAFT
How to prepare a LLM for an Exam? Closed-Book vs. Open-Book vs. RAFT
RAFT: Adapting Language Model to Domain Specific RAG 📚
Retrieval Aware Fine-Tuning (RAFT), presents a novel recipe to prepare fine-tuning data to tailor the models for domain-specific open-book setting, equivalent to in-domain RAG. In RAFT, we prepare the training data such that each data point contains a question (
We demonstrate that our RAG approach trains the model to perform better RAG on the set of documents it is trained on i.e., in-domain. By removing the oracle documents in some instances of the training data, we are compelling the model to memorize domain-knowledge. The training data for RAFT is as follows, and an example training data can be seen in the figure below:
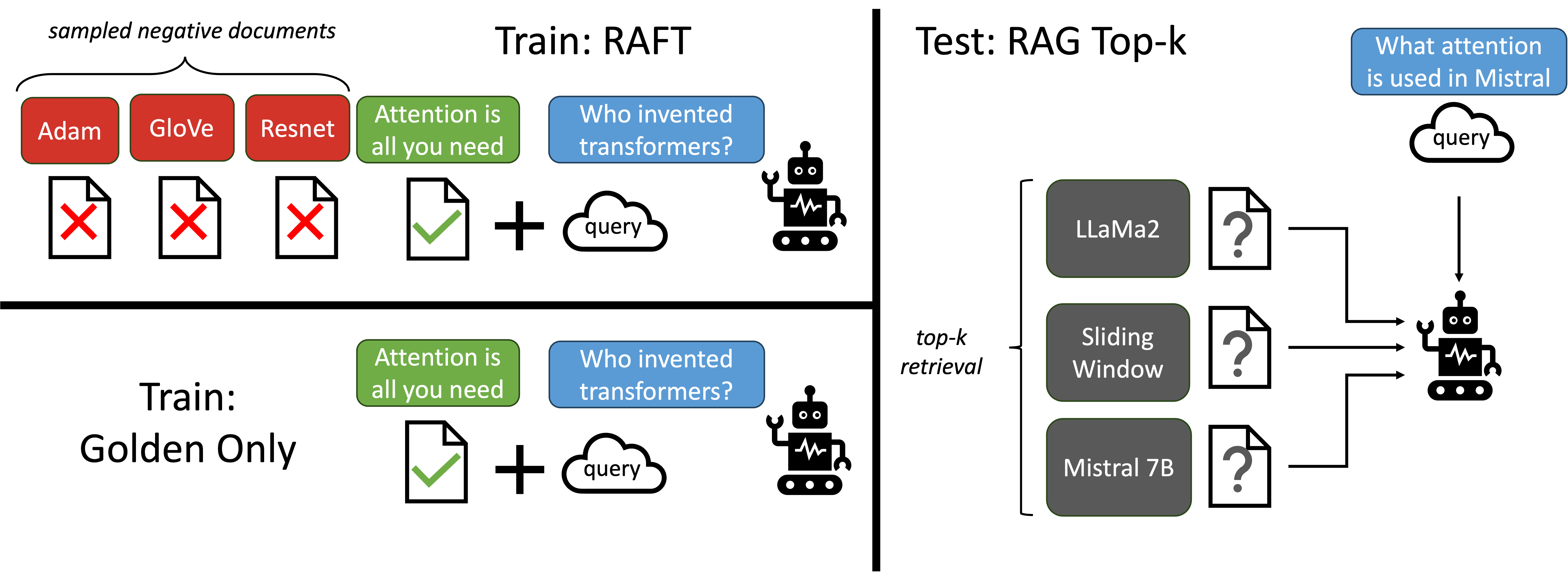 Train and Test Configuration for RAFT
Train and Test Configuration for RAFT
We also provide one example of training data of our dataset. This involves questions, context, instruction and final CoT answer. In our answer, we use ##begin_quote## and ##end_quote## to denote the beginning and end of a quote that is directly copy pasted from the context. We found this an efficient way to prevent the model hallucinate and stick to the contexts provided.
Question: The Oberoi family is part of a hotel company that has a head office in what city?
context: [The Oberoi family is an Indian family that is famous for its involvement in hotels, namely through The Oberoi Group]...[It is located in city center of Jakarta, near Mega Kuningan, adjacent to the sister JW Marriott Hotel. It is operated by The Ritz-Carlton Hotel Company. The complex has two towers that comprises a hotel and the Airlangga Apartment respectively]...[The Oberoi Group is a hotel company with its head office in Delhi.]
Instruction: Given the question, context and answer above, provide a logical reasoning for that answer. Please use the format of: ##Reason: {reason} ##Answer: {answer}.
CoT Answer: ##Reason: The document ##begin_quote## The Oberoi family is an Indian family that is famous for its involvement in hotels, namely through The Oberoi Group. ##end_quote## establishes that the Oberoi family is involved in the Oberoi group, and the document ##begin_quote## The Oberoi Group is a hotel company with its head office in Delhi. ##end_quote## establishes the head office of The Oberoi Group. Therefore, the Oberoi family is part of a hotel company whose head office is in Delhi. ##Answer: Delhi
Example of our RAFT training data.
RAFT Evaluation 📊
In our experiments, we use the following datasets to evaluate our model and all baselines. We select these datasets from both popular and diverse domains including Wikipedia, Coding/API documents, and medical question answering.
- Natural Questions (NQ), Trivia QA and Hotpot QA are the open-domain questions based on Wikipedia, mainly focused on common knowledge (e.g., movies, sports, etc).
- HuggingFace, Torch Hub, and TensorFlow Hub are from the APIBench proposed in the Gorilla paper. These benchmarks mainly concern about how to generate correct functional API calls based on the documentation.
- PubMed QA is the question-answering dataset tailored only for biomedical research question answering. It mainly focuses on answering medical and biology questions based on a given set of documents.
We consider the following baselines for our experiments:
- LlaMA2-7B-chat model with 0-shot prompting: this is the commonly used instruction-tuned model for QA tasks, with clearly written instructions but no reference documentation.
- LlaMA2-7B-chat model with RAG (Llama2 + RAG): similar to the previous setting, but differently we add on the reference context. This is the most used combination when dealing with domain-specific QA tasks.
- Domain-Specific Finetuning with 0-shot prompting (DSF): Performing standard instruction-finetuning without documents in the context.
- Domain-Specific Finetuning with RAG (DSF + RAG): Equip a domain-specific finetuned model with external knowledge using RAG. So, for the "knowledge" the model doesn't know, it can still refer to the context.
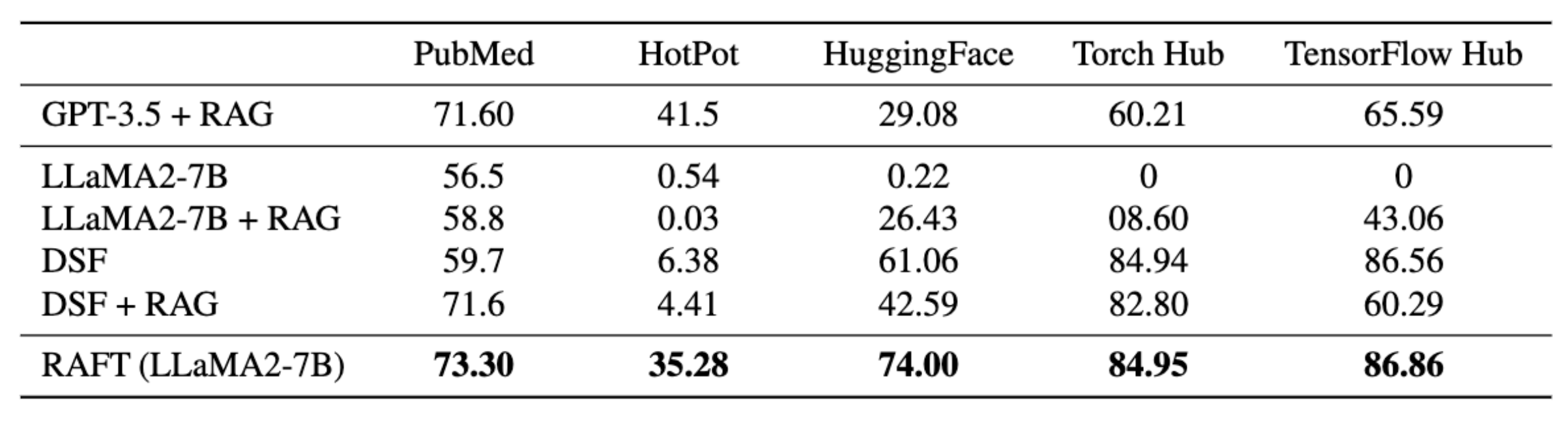 Results of RAFT on Medical (PubMed), General-knowledge (HotPotQA), and API (Gorilla) benchmarks.
Results of RAFT on Medical (PubMed), General-knowledge (HotPotQA), and API (Gorilla) benchmarks.
Train your own RAFT 💡
We specially thanks to Microsoft and Meta for the joint blog and enabling us to train your own RAFT model with Llama2-series models and Azure AI Studio. The following steps are a short tutorial on how to train your own RAFT model for RAG applications, starting from dataset preparation, to model finetuning and finally model deployment.
Dataset Preparation: We provide one example to prepare the dataset for RAFT. The dataset is a collection of questions, context, and answers. The context is a collection of documents, and the answer is a chain-of-thought style answer generated from one of the documents with the help of GPT-4. Please see one example below.
Question: The Oberoi family is part of a hotel company that has a head office in what city?
context: [The Oberoi family is an Indian family that is famous for its involvement in hotels, namely through The Oberoi Group]...[It is located in city center of Jakarta, near Mega Kuningan, adjacent to the sister JW Marriott Hotel. It is operated by The Ritz-Carlton Hotel Company. The complex has two towers that comprises a hotel and the Airlangga Apartment respectively]...[The Oberoi Group is a hotel company with its head office in Delhi.]
CoT Answer: ##Reason: The document ##begin_quote## The Oberoi family is an Indian family that is famous for its involvement in hotels, namely through The Oberoi Group. ##end_quote## establishes that the Oberoi family is involved in the Oberoi group, and the document ##begin_quote## The Oberoi Group is a hotel company with its head office in Delhi. ##end_quote## establishes the head office of The Oberoi Group. Therefore, the Oberoi family is part of a hotel company whose head office is in Delhi. ##Answer: Delhi
Model Finetuning: We would train the model to output the CoT answer based on the question and the provided context. The base model, Llama2-7B is suitable for RAG tasks, where the tasks require a combination of the model's ability to reason, understand language, have lower-latency inference, and be easily adaptable to diverse settings. Llama2-7B fit the bill well- it's a good base model for a lot of the general-knowledge, question-answering tasks, with encouraging math skills, and the ability to parse reasonably long documents due to its 4k pre-training. Llama2-7B is also a perfect model for training on 4 A100-40G GPUs and serving on a single one. Thereby in the pareto curve or performance, ease-of-deployment, and with the right licensing, the LLaMA2 model is quite apt for the RAFT task. With the help of Microsoft AI studio, users can also explore Llama-13b or 70b as well. Below is a screenshot that shows the model finetuning process on Azure AI Studio.
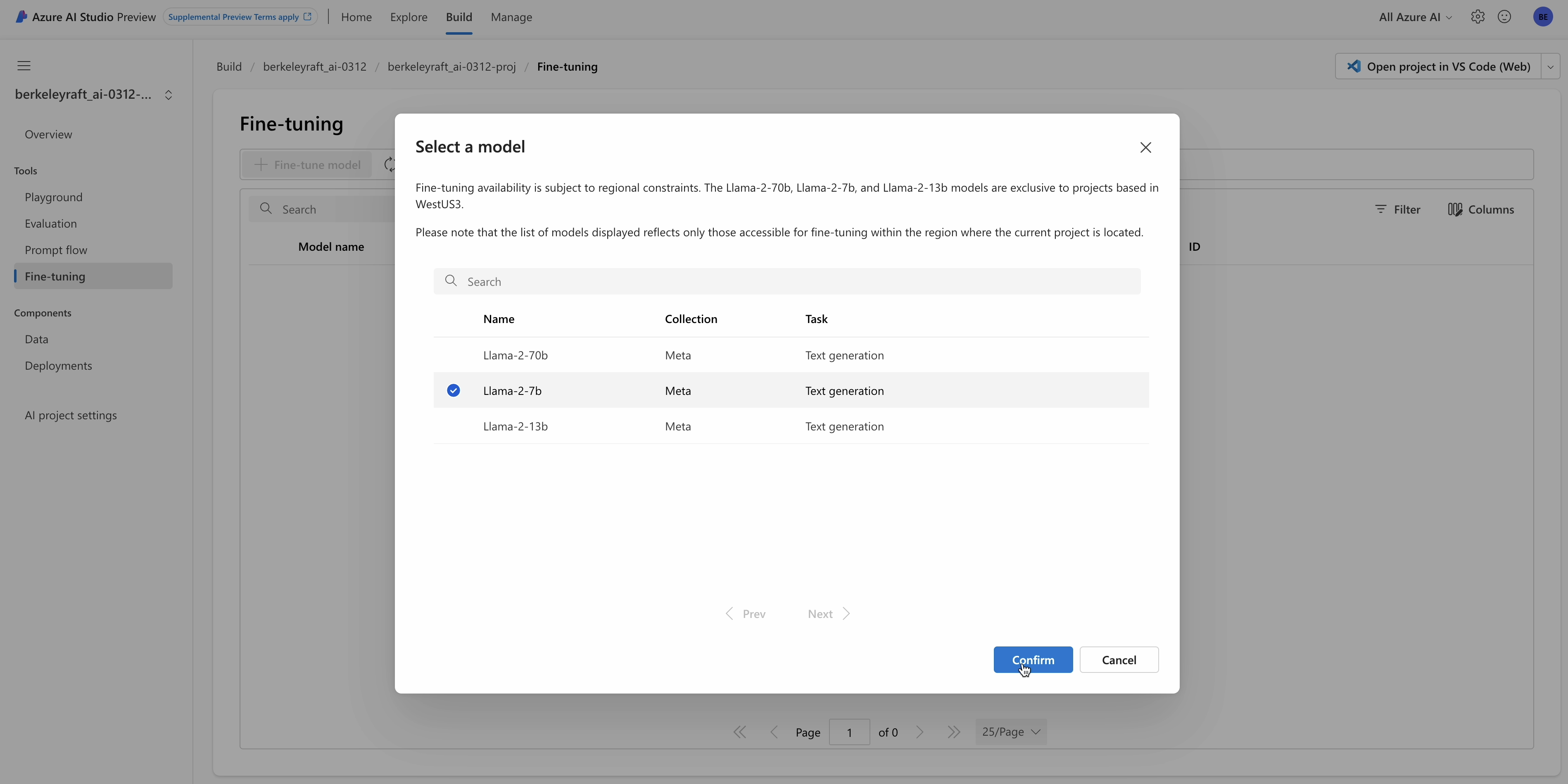 Finetune Llama2-7B on Azure AI Studio
Finetune Llama2-7B on Azure AI Studio
Model Deployment: Once the model is trained, you can freely deploy it on your own GPUs (or CPUs through llama.cpp); an alternative is to deploy it on Microsoft AI Studio. The following image shows the model deployment process on Azure AI Studio. Thanks to the help of Meta Llama-2 and Microsoft AI Studio, it is easy to fine-tune and deploy LLMs for enterprises, greatly enabling the deployments of custom models for different enterprises.
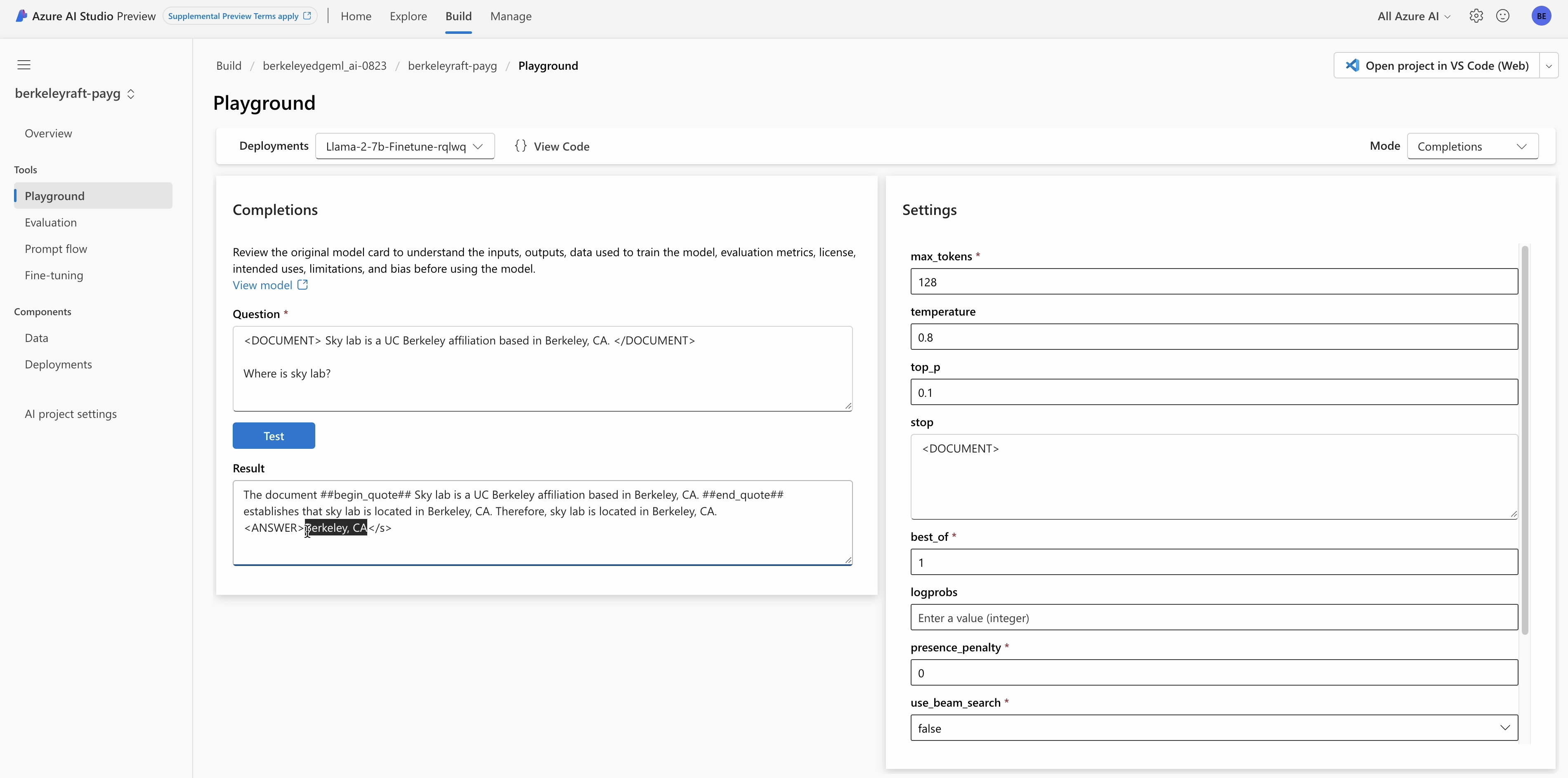 Deploy Llama2-7B on Azure AI Studio
Deploy Llama2-7B on Azure AI Studio
Conclusion
RAFT is a training strategy designed to enhance the model's performance in answering questions within a specific domain, in "open-book" settings. This technique demonstrates a fine-tuning recipe for LLMs for question-answering tasks based on a selected collection of documents. We have pinpointed several crucial design decisions, such as training the model alongside distractor documents, organizing the dataset so a portion lacks oracle documents in their context, and formulating answers in a chain-of-thought manner with direct quotations from the relevant text. Our evaluations on PubMed, Hotpot QA, and Gorilla API Bench underline RAFT's significant potential. Looking forward, we anticipate that in-domain Retrieval-Augmented Generation (RAG) will continue to gain interest within both industrial and academic spheres. Unlike general-RAG, our work addresses practical scenarios where LLMs are tasked with answering questions using domain-specific knowledge. Aligning with current trends, our findings suggest that smaller, fine-tuned models are capable of performing comparably well in domain-specific question-answering tasks, in contrast to their generic LLM counterparts.
We hope you enjoyed this blog post. We would love to hear from you on Discord, Twitter (#GorillaLLM), and GitHub.
If you would like to cite RAFT:
@inproceedings{raft2024,
title={RAFT: Adapting Language Model to Domain Specific RAG},
author={Tianjun Zhang and Shishir G. Patil and Naman Jain and Sheng Shen and Matei Zaharia and Ion Stoica and Joseph E. Gonzalez},
year={2024},
journal={arXiv preprint arXiv:2403.10131}
}